


In our last article, we introduced Sub-ML use cases and discussed how their number is growing. In this article, we’ll try and understand how purpose built feature stores for solving Sub-ML use cases can help drive more value with data.
Data Science as a discipline has seen the kind of evolution that only few others have. What started as a combination of applied statistics and computer science has enabled powerful data-driven decision making and predictions to solve real world problems. To illustrate this further, think of all the complex Data Warehousing and Business Intelligence solutions companies use to mine data and analyze and visualize results for decision-makers. With time, the size and number of data sets increased, complexities grew, and practitioners shifted to Big Data and Machine Learning.
Today, we see Business Intelligence (BI) and Machine Learning (ML) coexist as functions across data-driven organizations. However, although the end goal of each function is to provide users with actionable inputs for decision-making with their data, their end-consumers, implementation complexity, and design practices are remarkably different. Furthermore, each function comes with its own set of challenges:
-
BI tools can only handle a limited amount of complexity and size of datasets. Their scope is limited when it comes to providing solutions to use cases with increasing degrees of complexity, primarily focused on decision making (e.g., credit risk, benchmarking, recommendations, RFM).
-
ML engineers and data scientists are expected to solve the challenge of decision-making. But, due to the lack of bandwidth (and unavailability of data science talent, not to mention the lack of prepared datasets taking up over 80% of the time), these use cases are often put on the backburner.
These challenges result in a backlog of questions, data scientists’ fatigue, and business stakeholders’ reluctance to adapt to a technological change. Although both ML and BI, which are on opposite ends of the spectrum, can orchestrate incredible gains, they can also be highly inefficient. The question becomes – is there a solution to overcome these inefficiencies?
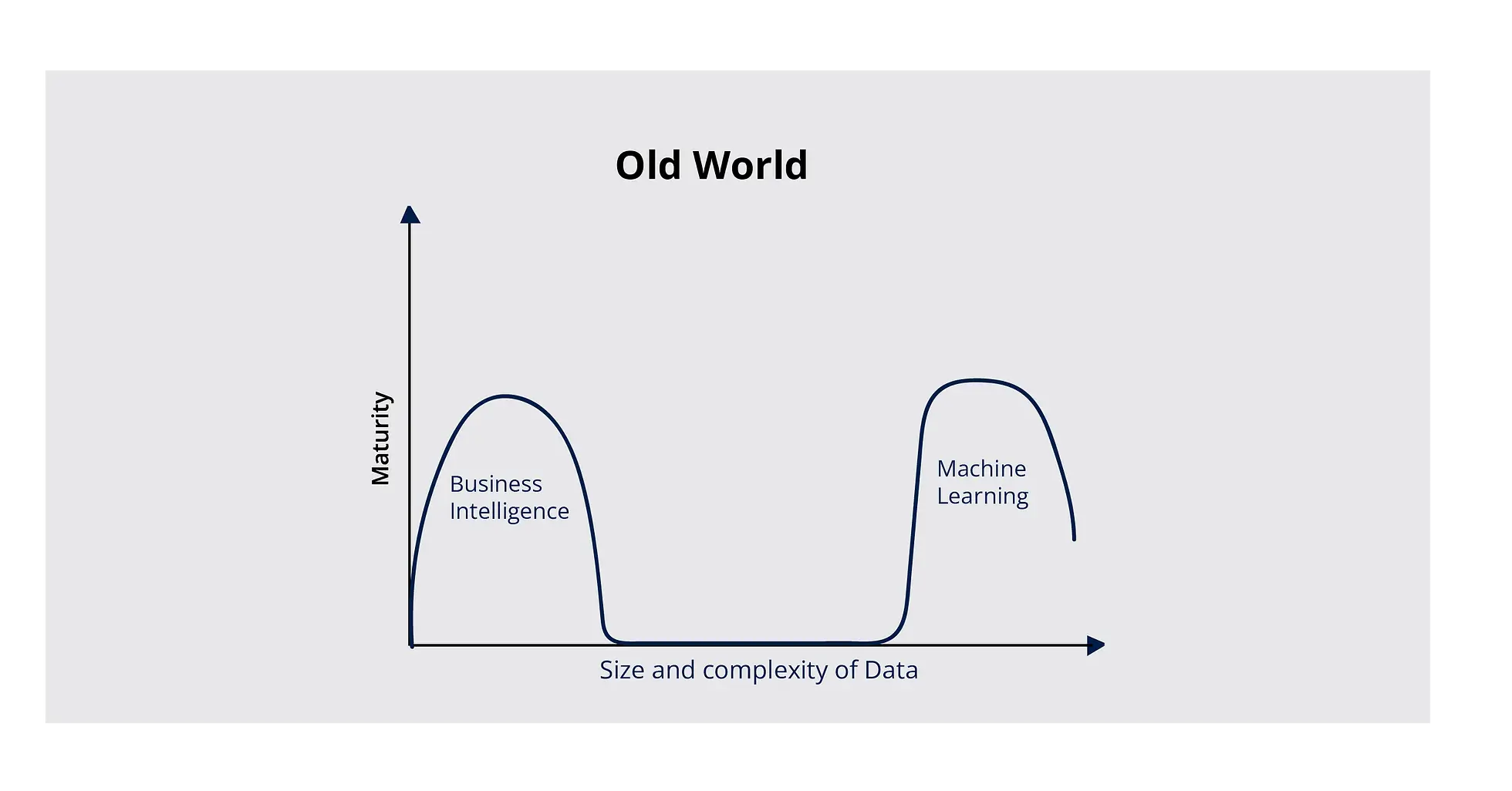
BI and ML are the traditional data practices on opposite ends of the spectrum.
According to Scribble Data’s internal study, over 62% of data and analytics leaders struggled to understand their data and feature sets (including the genesis of the location, modifications, and version history). It is no surprise that more than 60% of CEOs are skeptical about their data and spend more than 80% of their time preparing for consumption.
Businesses require usable data to be prepared and cleaned to generate models that address multiple use case requirements. And why is this important, you ask?
Let’s consider a simple model,
y = f(x)
Where x is your input vector, y is your output vector, and f is your model. And if you consider a column with different measurable values of x those would be your feature values.
It’s easy to see that the quality and accuracy of your output are dependent on your input or your feature values. And if your datasets (input) aren’t prepared or cleaned (which is a time-consuming and resource-intensive process), no amount of modeling will get you the right output to aid decision-making.
Given the amount of time taken for an ML model to go from planning to production, lasting several months, business stakeholders often tend to lose faith in ML-based projects. On the flip side, the cost of not investing time in data preparation is significant, as we recently saw in the case of a well-renowned realty startup whose inaccurate forecasting model cost them an entire business unit.
So how can companies strike that right balance?
The solution: Feature Stores.
Understanding Feature Stores
Organizations must make efficient use of all resources — data, models, and compute — as they continue to innovate in AI. A Feature Store is a service that consumes large amounts of data, adds features, and stores the results. A Feature Store makes it easier to register, discover, and use ML features as part of pipelines, making it simpler to transform and validate the training data fed into machine learning systems. Although feature stores can help with consistent feature engineering between training and inference, a significant number of use cases would not get the attention they deserve because they fall into the no man’s land between BI and ML.
Since most feature stores were built to solve ML challenges at some of the biggest tech companies in the world – Uber’s Michelangelo, AirBnB’s Zipline, Apple’s Overton, and others by Amazon, GoJek, Facebook, they may not be sufficient to serve the needs of 90% of smaller businesses and their problem statements/use cases.
Feature apps for end-to-end ML and Sub-ML use cases
While current feature stores (part of the “modern data stack”) have served big tech well with multiple developments over the years, the fact remains that decentralized, nimble decision-making in business functions is the need of the hour, with stakeholders expecting nothing less thanks to the rapid advancement of data science technology, the democratization of computing in the cloud, and the availability of data.
The significant set of problem statements and use cases that fall into the no-man’s land between BI and ML (due to the lack of the data science team’s bandwidth and being outside the capabilities of traditional BI tools), presents an opportunity for immediate impact and rapid scaling for fast moving businesses. Examples of such use cases include fraud detection, segmentation, classification, and business-specific recommendation and risk assessment models.
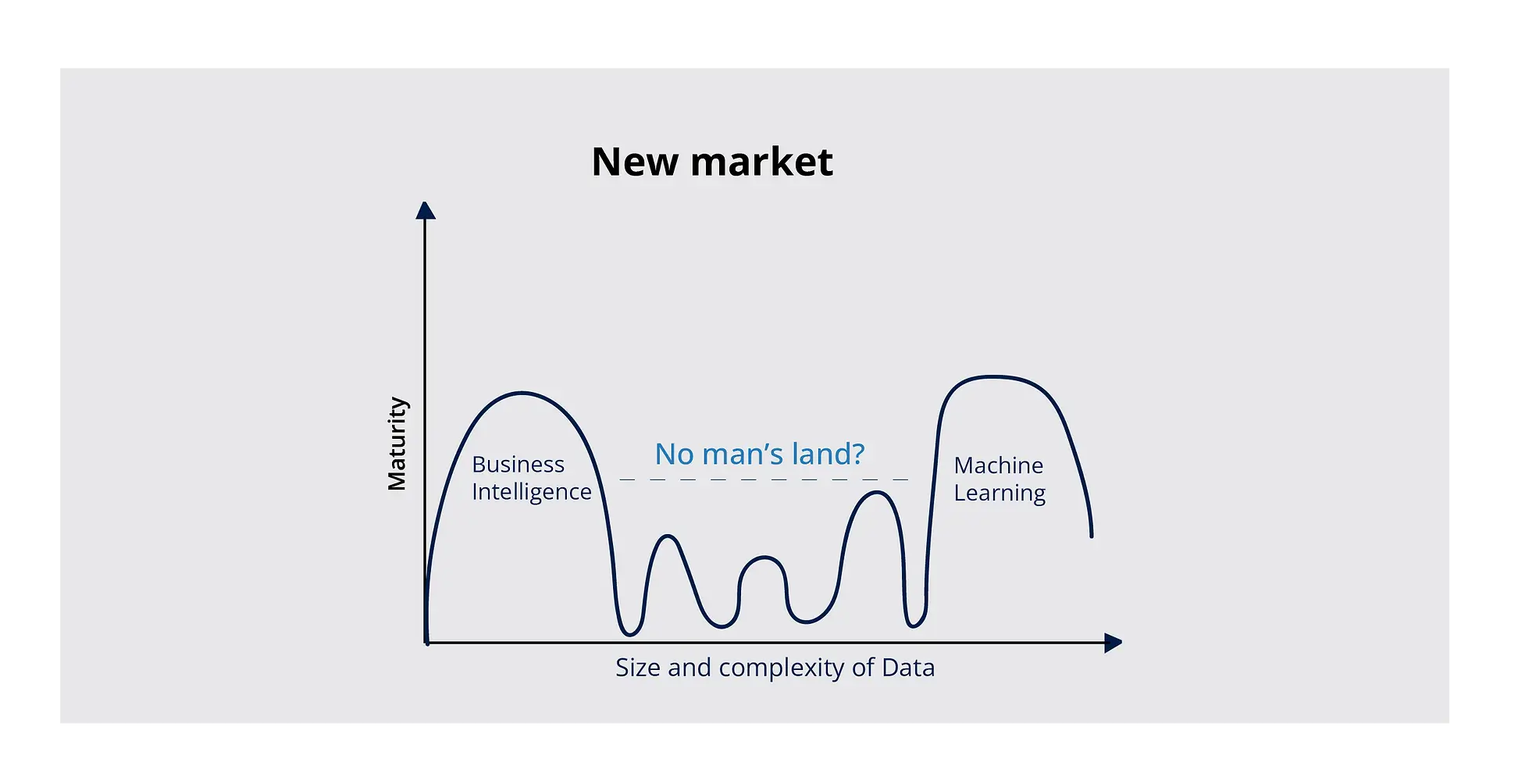
The “No Man’s Land” of medium complexity use cases between Business Intelligence and Machine Learning
Scribble Data’s modular Feature Store, Enrich takes care of business’s ML and Sub-ML use cases. The Enrich Feature App store builds and discovers prepared data assets & features, enables data practitioners to understand the context of data assets & features, and consume data assets and features across teams – internal and external, technical and non-technical.
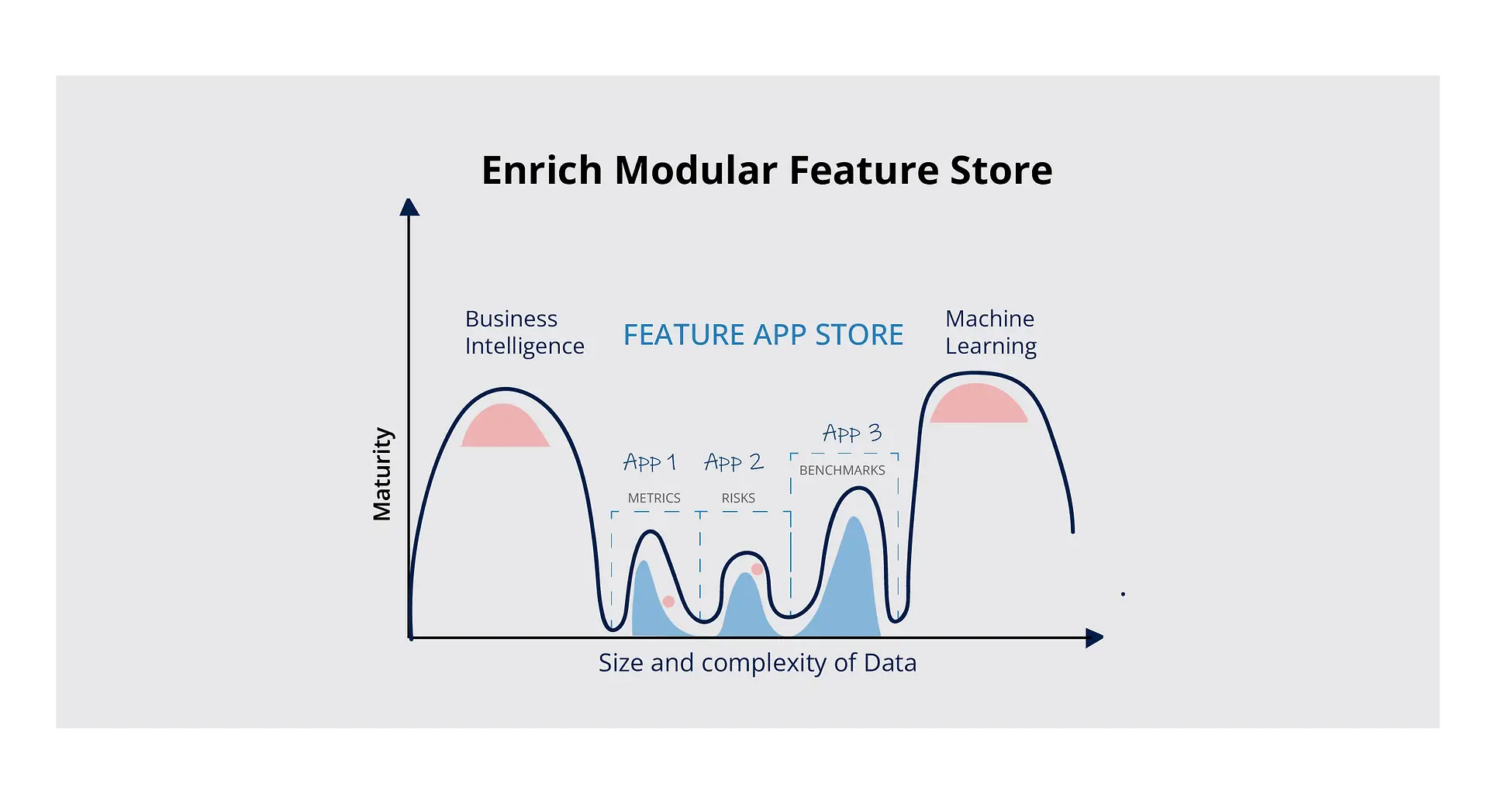
Enrich Modular Feature Store Provides Feature Apps that streamline feature engineering in specific contexts
Scribble Data’s Enrich is a modularized take on feature stores, with feature apps that integrate with customers’ existing data stacks to streamline feature engineering for their specific contexts. The feature apps cover a range of functionality, from metadata management and data cataloging to a metrics app that allows companies to search for and store KPIs and metrics across business verticals. Enrich also provides a powerful low-code configurable interface that allows data engineers and scientists to quickly create custom workflows for generating data assets and do so in an auditable, trustable manner.
Getting started with Sub-ML
According to Gartner’s Hype Cycle for AI – 2021, 70% of organizations will be compelled to shift their focus from big to small and wide data, providing more context for analytics and making AI less data-hungry. At Scribble Data, we’re betting on Sub-ML to take advantage of this small and comprehensive data and are already seeing 8x faster time to value (TTV).
Watch this space for our next article on Sub-ML and Sub-ML use cases, where we talk about data science and Sub-ML economics.
If you’d like to know more about whether a shift in focus to Sub-ML can benefit your business, schedule a call with our experts by writing to us at hello@scribbledata.io.