


As industries across the globe attempt to adapt to the big data architecture, expensive and ineffective feature engineering practices mean that businesses are very likely to “hit a wall” when it comes to organizing their machine learning operations (MLOps). A lot of time is consumed in data ingestion, and lackluster machine outputs indicate that stakeholders may lose faith in the entire ML infrastructure. How do we avoid this situation?
The answer is “feature stores”. Albeit overused, but accurate: if data is our new oil, then the datasets ML models are trained with–or, to be more precise, its features, are the oil gushers.
An ML model is only as good as the data it is trained with; feature stores have become an essential component of the ML stack. They are able to centralize and automate data process management that powers ML models in production while also allowing analytical experts to construct and deploy features rapidly and reliably.
What Do We Mean by Features in ML?
For most use cases, the training datasets fed into the ML model can be visualized as a two-dimensional table where rows indicate examples and columns are attributes describing them. This is where the concept of features comes into play.
A feature is any quantifiable property or characteristic acquired from either a raw data point or an aggregation of data points. In short, features are the attributes that describe a dataset.
Choosing high-quality–descriptive and independent features is crucial for driving effective algorithms. How these features are selected and implemented generally depends on the model function and the predictions it is trying to generate. For instance, we can consider a transaction monitoring model which predicts whether a transaction is fraudulent or not. Some of the relevant features might be:
- Was the transaction amount unusual for the customer?
- Was it conducted in a foreign country?
- Was the amount larger than normal median values?
Now we can understand the importance of feature engineering: the better the features, the more accurate the model will be, which will ultimately yield better returns for the business implementing it.
Understanding Feature Stores
A feature store is a centralized location where features are cataloged and organized to be directly accessed by data scientists and data engineers for data-related tasks ranging from data visualization to adhoc insights generation, to training ML models to running inference on already trained models. However, a feature store is not only a data layer. The framework also supports data manipulation – you can create or update groups of features extracted from multiple data sources or generate new datasets from those feature groups.
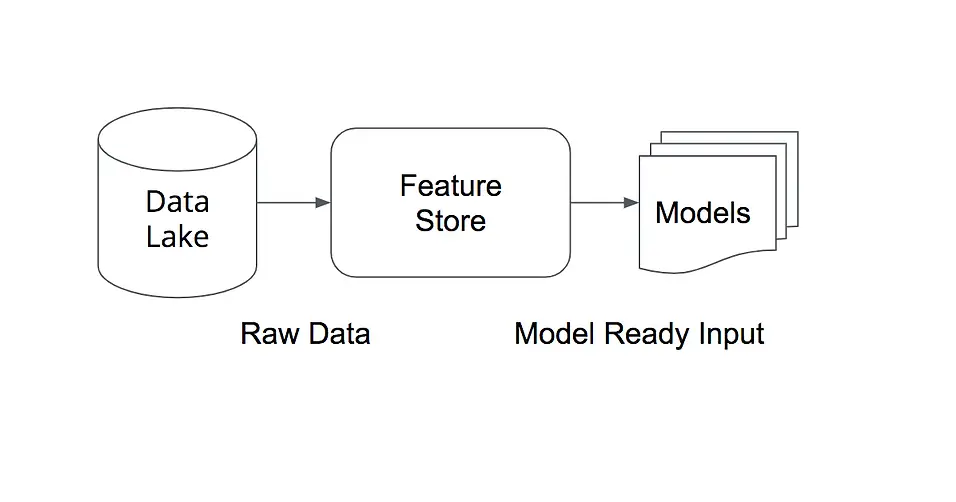
Some feature stores offer high throughput batch APIs for retrieving features during online predictions and acquiring point-in-time corrected training data. For example, let’s say that your next project involves an e-commerce recommendation system where search queries need to be personalized. When a user issues a query, generally, it will be executed on a stateless web application. The query itself will be information poor as it only contains some text and session/user ID at most. However, the initial information-poor signal can be transformed into an information-rich signal by utilizing the user and session ID to retrieve numerous precomputed features from the feature store, enriching the queries with features representing the user’s history and features representing context (popular items).
Drawing from this application, we can see how feature stores encourage reproducibility and reusability for training datasets. As the productization of data science accelerates, the importance of feature stores advances as well:
“…we added a layer of data management, a feature store that allows teams to share, discover, and use a highly curated set of features for their machine learning problems. We found that many modeling problems at Uber use identical or similar features, and there is substantial value in enabling teams to share features between their own projects and for teams in different organizations to share features with each other.” – Uber’s Michelangelo Blog.
Features for Unstructured Datasets
So far, our discussion has been confined to the sphere of features for structured datasets. Probing further, where does the unstructured data–non-tabular data like images and texts, fit in this whole equation? For the most part, storing these datasets in a meaningful structure in feature stores isn’t a problem. For instance, data engineers can convert an image into a feature vector by assigning each pixel a value and apply techniques like term frequency and term frequency-inverse document frequency (TF-IDF) to determine the features of text-based unstructured datasets. This process of “embedding” is a crucial step in many deep learning (DL) models. Although such raw datasets are expensive to compute, embeddings of unstructured datasets form a good candidate for feature stores, especially for DL-based use cases.
Feature Store Architecture
We now know that a feature store primarily manages features. However, there are several related functions , including:
- Data ingestion
- Data transformation
- Data storage
- Data Serving
Considering these requirements, a typical feature store architecture comprises:
1. Storage
Offline features not required for immediate use are usually stored in data warehouses like AWS Redshift. On the other hand, time-sensitive online features are stored in low-latency cache stores like Redis, or Elasticsearch.
2. Automated Data Transformation
Data transformation pipelines are responsible for converting raw data into usable features as a part of the feature engineering process. Feature stores serve as a platform for managing and orchestrating these pipelines, whether they are scheduled pipelines that aggregate data at discrete intervals, on-demand pipelines, or real-time/streaming pipelines that update features in time-sensitive use cases and handle millions of events at scale, in real time.
3. Real-Time Feature Serving
Real-time feature serving allows the features to be constantly updated in real-time, which is particularly useful when models require the most recent updates to datasets for their algorithms to generate efficient predictions (e.g., weather forecasting models).
4. Feature Registry
This is a central repository used by data consumers to manage feature lists alongside their descriptions and metadata. APIs and UIs provide a central interface for data consumers to clearly see available features, pipelines, and training datasets.
5. Operational Monitoring
Although ML models may perform well in the initial validation stages, there’s always a probability of degrading correlation between the dependent and independent variables due to a phenomenon called model drift. Feature stores not only maintain data quality and correctness which keeps model drift at bay, it also makes it easier to keep track of metrics such as feature drift, prediction drift, and model accuracy.
Benefits of Feature Stores
If you still aren’t convinced about the usability of feature stores, the following reasons may make it more persuasive to incorporate this infrastructure in your organization’s day-to-day data-related needs.
- According to a survey by CrowdFlower, data preparation and cleansing accounts for nearly 80% of the work of data scientists. What’s worse is that much of the preparation work is unnecessary and repetitive as the same features and pipelines may have already been engineered by someone else, even within the same company. Therefore, feature stores allow for faster feature deployment as they abstract away the engineering layers and allow data consumers quick access to the data they need.
- Often while implementing ML models, the features used during the training process in the development environment are out of sync with the features in the production serving layer. Feature stores provide a smoother model deployment by ensuring a consistent feature set between the training and serving layer.
- Since the feature stores carry additional metadata for different features, data scientists are able to ascertain which sets of features will have a better impact on similar existing models, boosting the accuracy of the to-be-deployed model.
- Sharing is caring! As Machine Learning becomes more pervasive in our digital landscape, the number of AI projects and features, too, rises exponentially. Dealing with such large volumes of features tends to be inefficient and lacks a comprehensive overview. Even in large organizations, teams often end up with similar solutions just because they weren’t aware of another team’s task. In such an environment, feature stores promote better collaboration between different domains by avoiding work duplication and sharing metadata with peers.
- It is essential to keep track of a model’s lineage to ensure better data governance. Once again, this can be achieved through feature stores as they provide all the necessary tracking information regarding how a feature was generated, alongside insights and reports for regulatory compliance.
Examples of Different Feature Store Architectures
1. Michelangelo Palette is Uber’s feature store, which makes scaling AI easy, considering the influx of rich data and an ever-growing customer base. Its core is designed around frameworks like HDFS, Hive, and Spark, allowing scalable computations. Its capabilities are:
| Capability | Implementation |
| Input Correctness | Custom / outside the system |
| Feature Computation & Performance | HiveQL & Spark for batch features, FlinkSQL & Kafka aggregations for realtime features
Feature Transformers (UDFs) but at record level, bootstrapping of transformers |
| Trust & Discovery | Indirectly via monitoring |
| Storage | Hive for batch, Cassandra for realtime |
| Serving & Monitoring | Library abstraction to gather features from Hive, Cassandra, API, and feature Metadata
Cache layer to speed up serving Automatic monitoring of all computation pipelines |
2. SurveyMonkey is rather interesting because, unlike Uber’s Michelangelo, it operates at a different scale with a dozen of ML use cases. In short, the system is simpler, maintainable, and more fit-for-purpose. Some of its capabilities are:
| Capability | Implementation |
| Input Correctness | Custom/outside the system |
| Feature Computation & Performance | Hive queries for batch
Reusable |
| Trust & Discovery | Explicit validation before storing
UI to discover features and attributes |
| Storage | S3 with Athena/other interfaces for batch
NoSQL for realtime features |
| Serving & Monitoring | Library abstraction to gather features BigQuery & Redis |
3. Featureform is an emerging class of feature stores known as virtual feature stores. Such feature stores are characterized by providing a layer of abstraction atop an organization’s existing infrastructure to replicate the components of a feature store. Organizations are free to choose their own underlying technologies for each component. For instance, transform compute could be handled by Spark or Flink, computed features could be stored in Redis or another fast cache lookup for inference, and in S3 for adhoc analysis. The virtual feature store manages and orchestrates data transforms, but does not do the actual compute operations. In effect, a virtual feature store is more a framework and a set of steps defined as a workflow, than it is data infrastructure.
| Capability | Implementation |
| Input Correctness | Custom/outside the system, specific transforms are responsible |
| Feature Computation & Performance | User-selected compute engine |
| Trust & Discovery | Custom/outside the system, abstraction layer atop user-defined store |
| Storage | User-selected storage layer |
| Serving & Monitoring | User-selected serving layer |
4. Feast is an open-source feature store which was developed by GoJEK, Southeast Asia’s leading ride-hailing app and later acquired by Tecton. FEAST is focused on the serving and monitoring of the feature through a simple API. By standardizing dataflows, naming and computations FEAST leverages BEAM and BigQuery to simplify the overall system.
| Capability | Implementation |
| Input Correctness | Custom/outside the system |
| Feature Computation & Performance | Rich transformations expressible as BEAM queries and pipelines
Cover both realtime and batch paths using the same system |
| Trust & Discovery | Indirectly via monitoring |
| Storage | BigQuery is primary storage+computation mechanism |
| Serving & Monitoring | Library abstraction to gather features BigQuery and Redis |
4. Enrich is Scribble Data’s very own customizable feature store. Whereas large organizations deal with deploying ML solutions, there are thousands of small to mid-sized organizations that have raw data and want to generate value from it but don’t have the resources and high cost talent to build out ML solutions. Instead, there is emerging a class of solutions known as Sub-ML (or ML at reasonable scale) which is characterized by fast time-to-value and low-code/no-code interfaces while still requiring the guarantees of data correctness, reliability and availability. Enrich Sub-ML feature store allows data engineers and scientists to build features by providing a set of robust capabilities to transform raw data including metadata management, feature cataloging, visual debugging, knowledge management, and version tracking. Enrich also includes a low-code app store for building data apps for the consumption of prepared datasets by non-technical business users. Its capabilities are:
| Capability | Implementation |
| Input Correctness | Explicit quality checking / output validation |
| Feature Computation & Performance | Transform development framework that can be used with Pandas, Spark etc.
Feature metadata service |
| Trust & Discovery | Unit test support
Automatic documentation, provenance metadata collection Checkpoints and expectations support Feature app marketplace and provenance search |
| Storage | Flexible, SQL + NoSQL such as S3, Cassandra, and Redis |
| Serving & Monitoring | Custom for each deployment |
Selecting a Feature Store
With a plethora of options available–managed or open source, standalone or part of a broader ML platform, on-premise or on public cloud, selecting the right feature store for your business can get overwhelming. We’ve put together a quick framework that will help you make the right choice based on your business needs and your existing data stack.
- First things first, you need to assess whether your organization requires a feature store or not. The answer is likely to be a yes if:
- Models have to be frequently (re)trained.
- You have a large data team.
- Model combinations and thresholds exceed a certain threshold.
- Error-related costs are high, and you are therefore required to systematically build and manage features. And it’s not just big-ML, the long tail of business use cases require what we call a Sub-ML feature store as well
- You will also need to analyze whether the product’s commercial characteristics meet your organization’s needs. The criteria can include:
- Whether 24/7 support is available
- If the product is open-source, commercial software, or a managed cloud service?
- If the product is available in your public cloud, or on-premise
- The pricing models
- If it’s a standalone feature store or a part of a broader platform?
- Finally, you need to ensure that the feature store can be seamlessly incorporated across your operational data workflow. The architecture of the feature store should be assessed to see if it supports functionalities like feature sharing and discovery, a framework for creating feature definitions with the ability for your data teams to collaborate, online serving, feature ingestion, security and data governance, monitoring and alerting, and so on. And most importantly, it’s important to see if it provides seamless integration with your existing data stack.
Summary
Given everything we have discussed – from what constitutes features in ML to the broad definition of feature stores and their architectural design and benefits, it’s plain to see that feature stores are becoming an essential part of the data stack. Some of the largest tech giants have built their own feature stores, which is a good indication for the rest of the enterprises how vital it is to integrate feature stores in their data infrastructure to construct an efficient Machine Learning pipeline.
If you’re wondering how you can leverage a feature store that can help you solve a wide variety of use cases across varying levels of complexity, drop us a note – we’d be happy to chat. Scribble Data’s Enrich platform provides you with a robust and nimble framework to build, understand and consume your features.
Want to learn more about Feature Stores and how Scribble Data can help?
Do check out Carver Agents’ RegWatch – our new AI solution for real-time contextual regulatory risk intelligence, built for risk and strategy executives. Think of it as agentized mid-market LexisNexis. Visit https://carveragents.ai/.