

Hasper GenAI Platform
Purpose-built platform that brings the power of generative AI and machine learning to enterprise workflows

Faster and Accurate
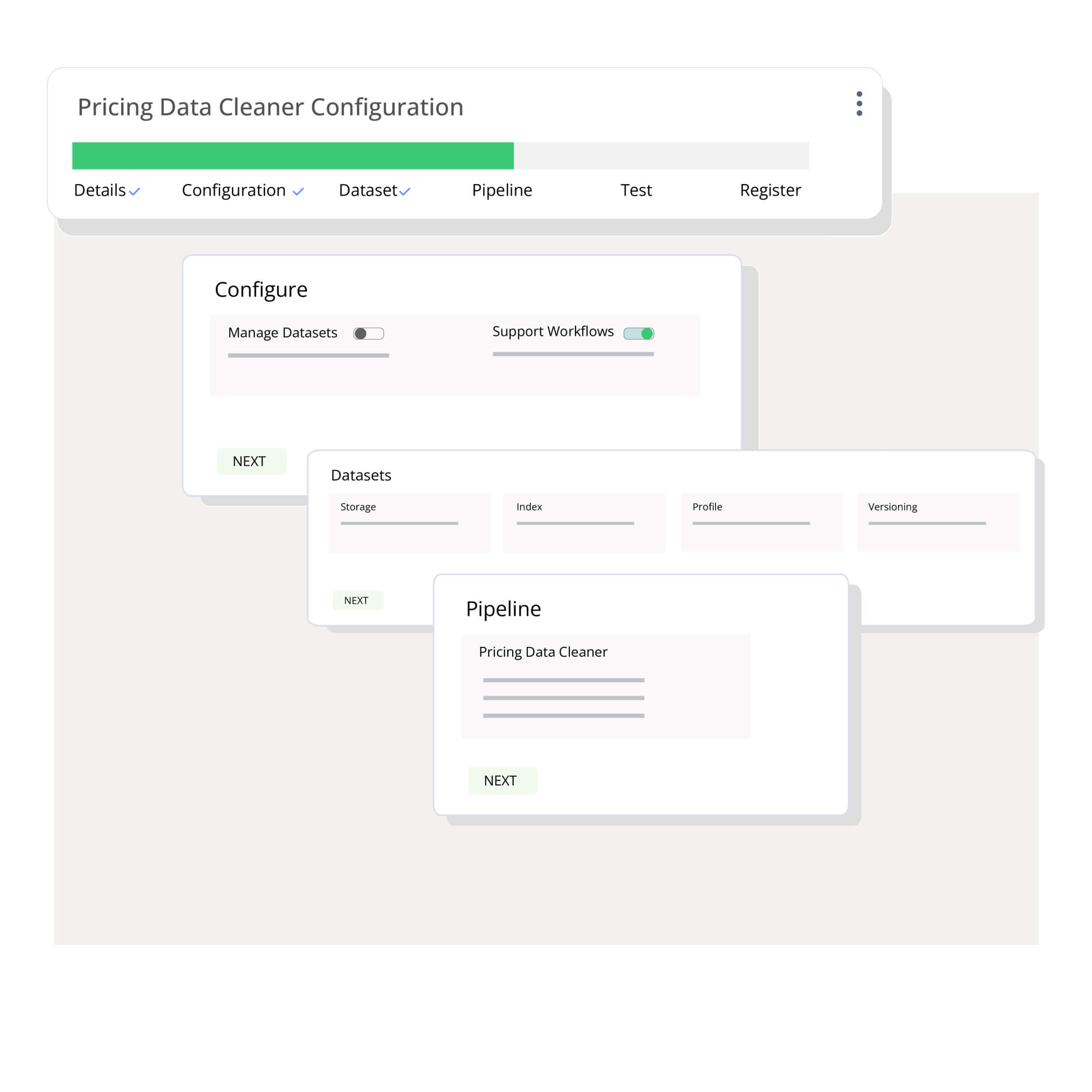
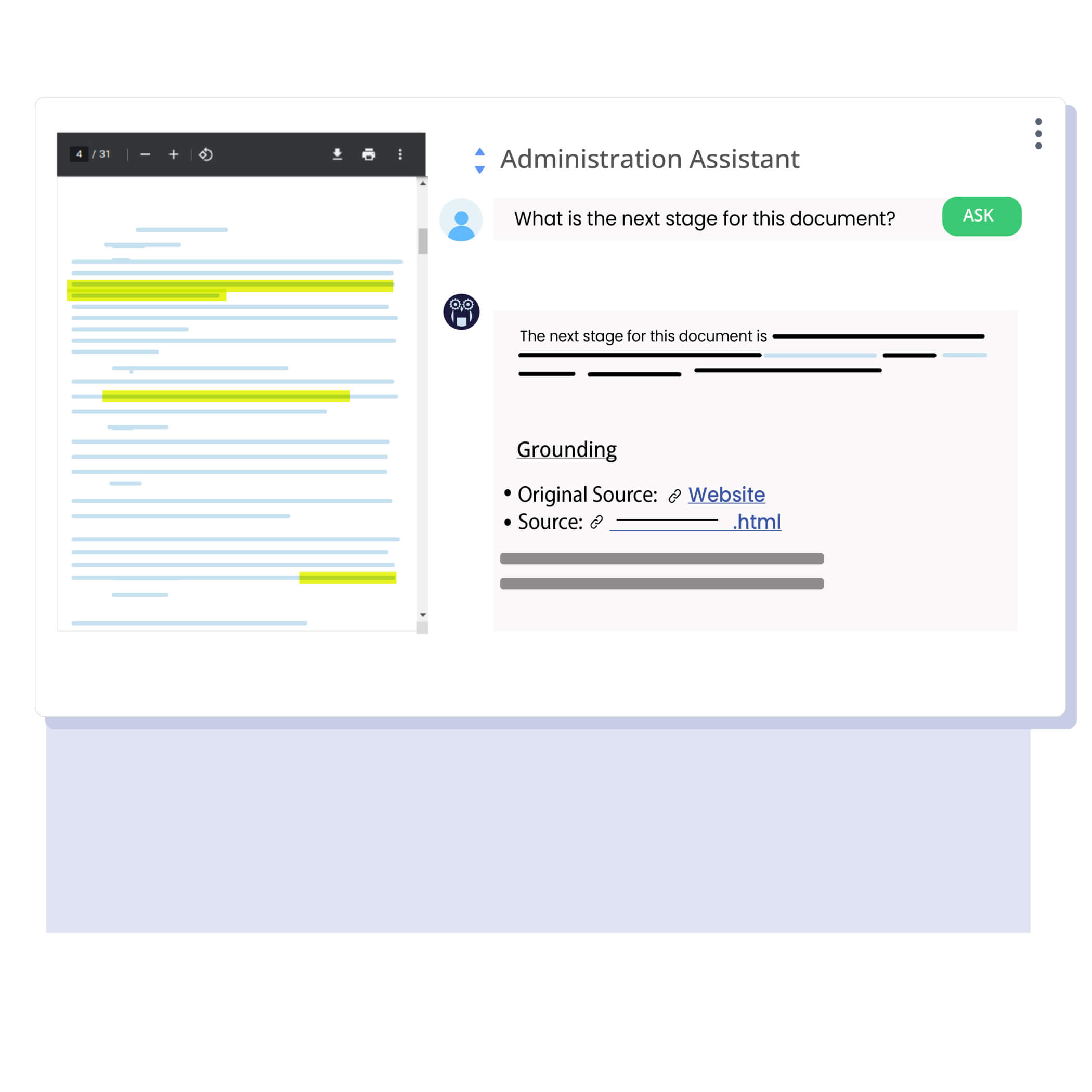
Go from concept to a production-grade assistant in a few minutes. Experience the power of AI/ML without the operational complexities.
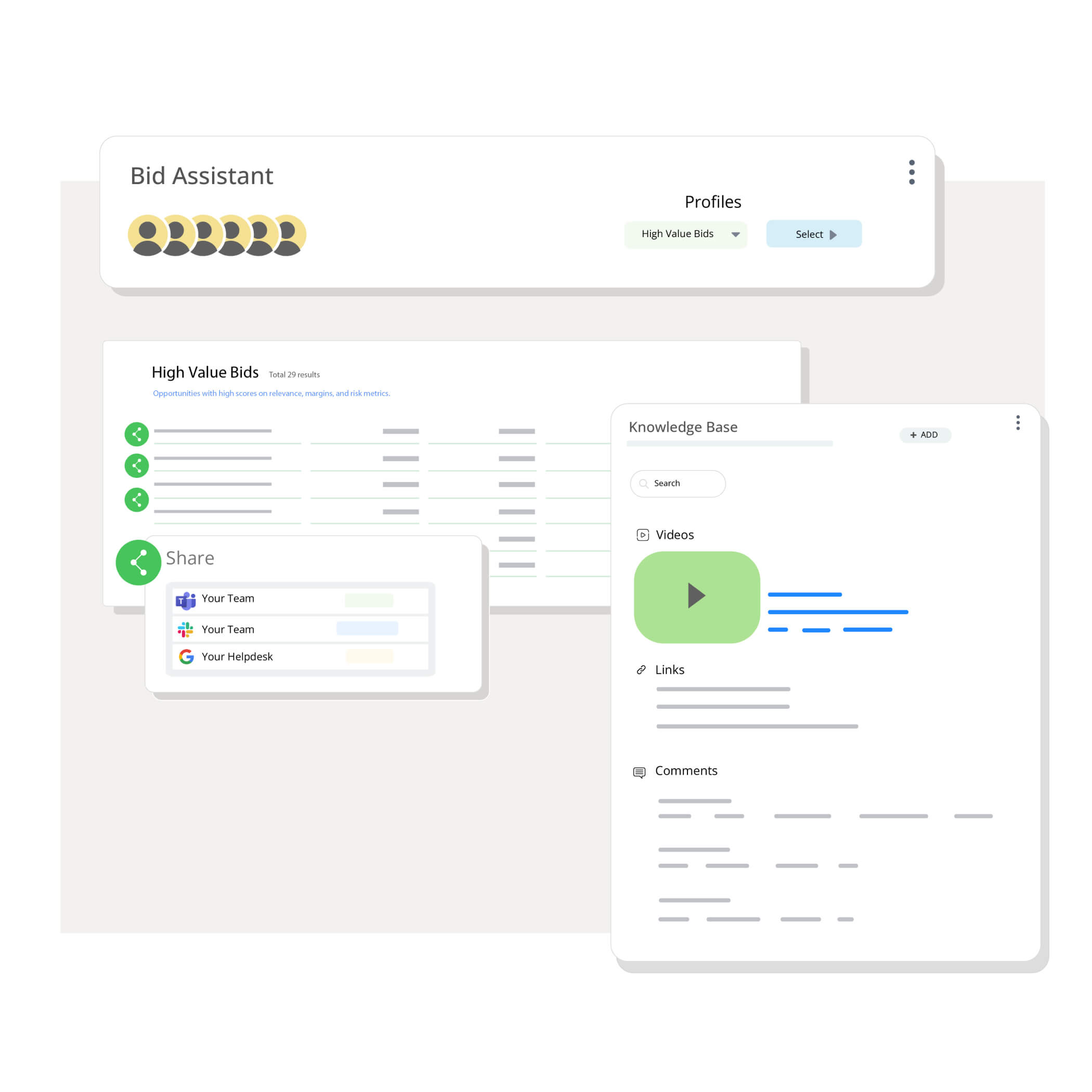
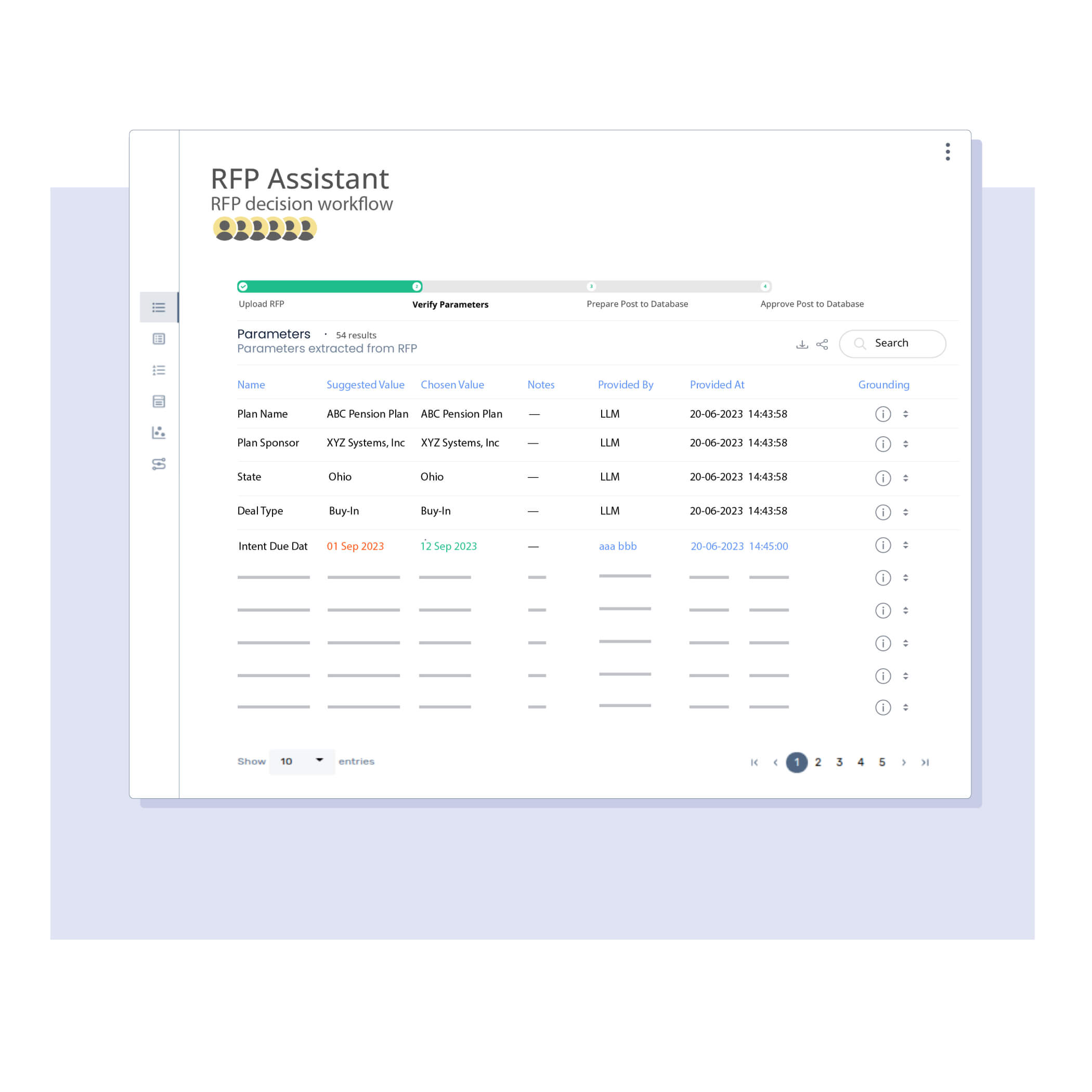
Improve productivity by collaborating on high-value use cases, complex workflows, and application integrations to eliminate silos, promote knowledge sharing, and streamline processes.
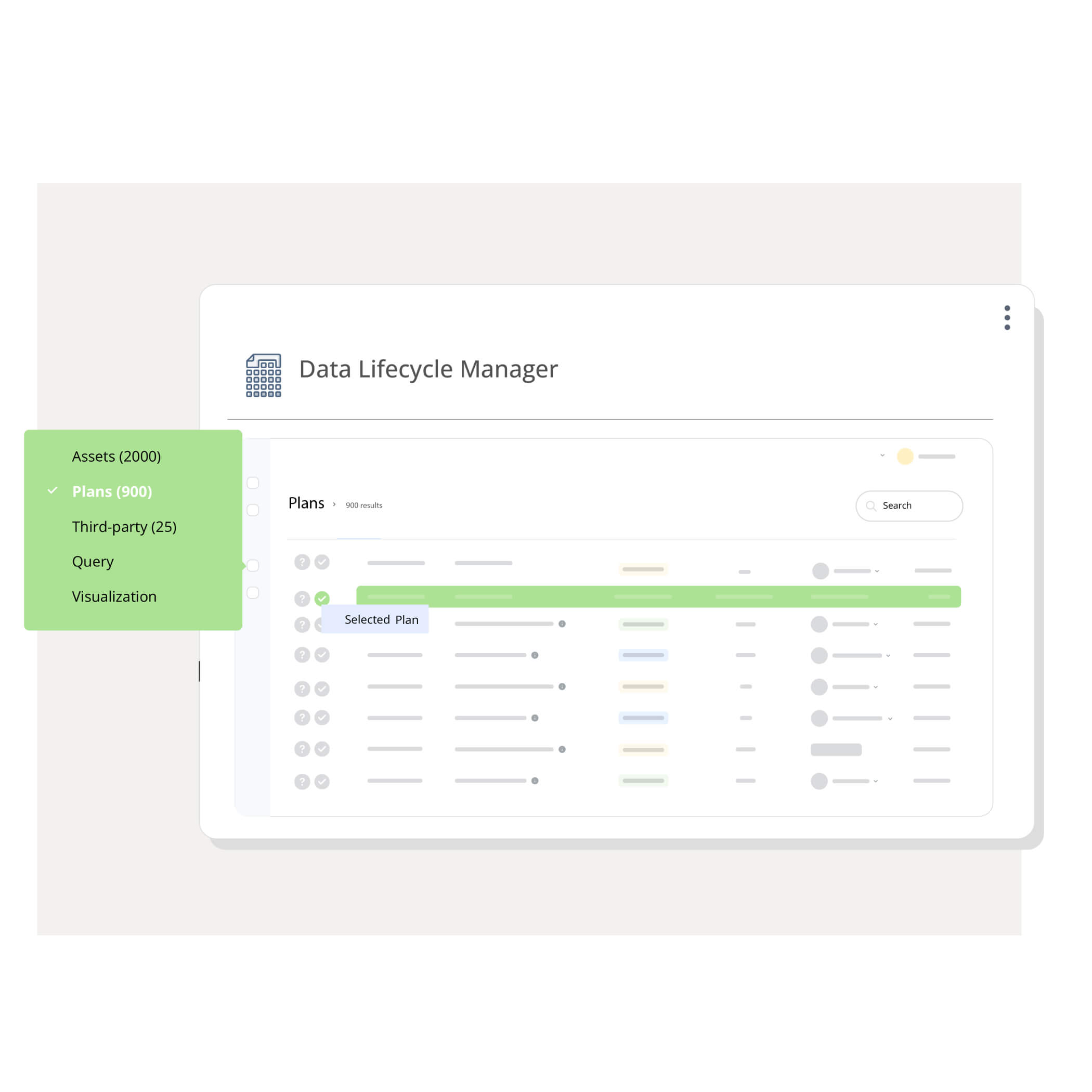
Manage data lifecycle across all stages of business workflows transparently, consistently, and efficiently. Utilize reusable workflows, transformations, and datasets to build GenAI/ML assistants faster and more efficiently.
Humanized Expertise with Hasper
Build context-appropriate workflows using Hasper's modular architecture for seamless integration into organizational processes, boosting speed and productivity.
Super-charge LLMs with domain-specific agents for highly accurate results. Hasper combines grounding, auditable prompt engineering, ML, and result post-processing for continuous improvements in relevance, accuracy, and user experience.
Leverage hybrid data products that integrate analytics, ML, and natural language to meet diverse business requirements. Hasper ensures policy-based execution, delivering within defined guardrails for security and privacy compliance.
Reliable
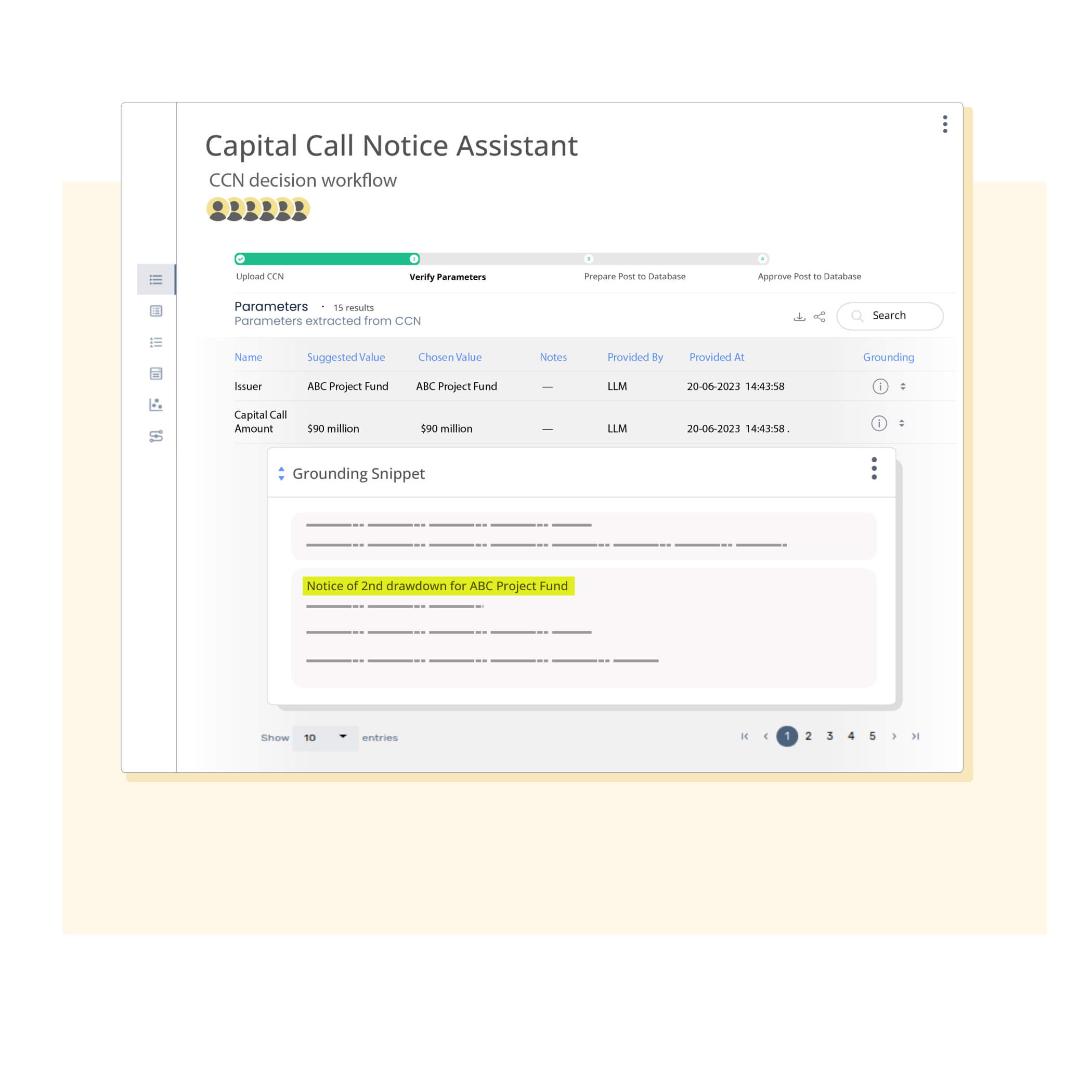
Enhance accuracy and confidence by combining AI with human expertise for reliable outcomes.
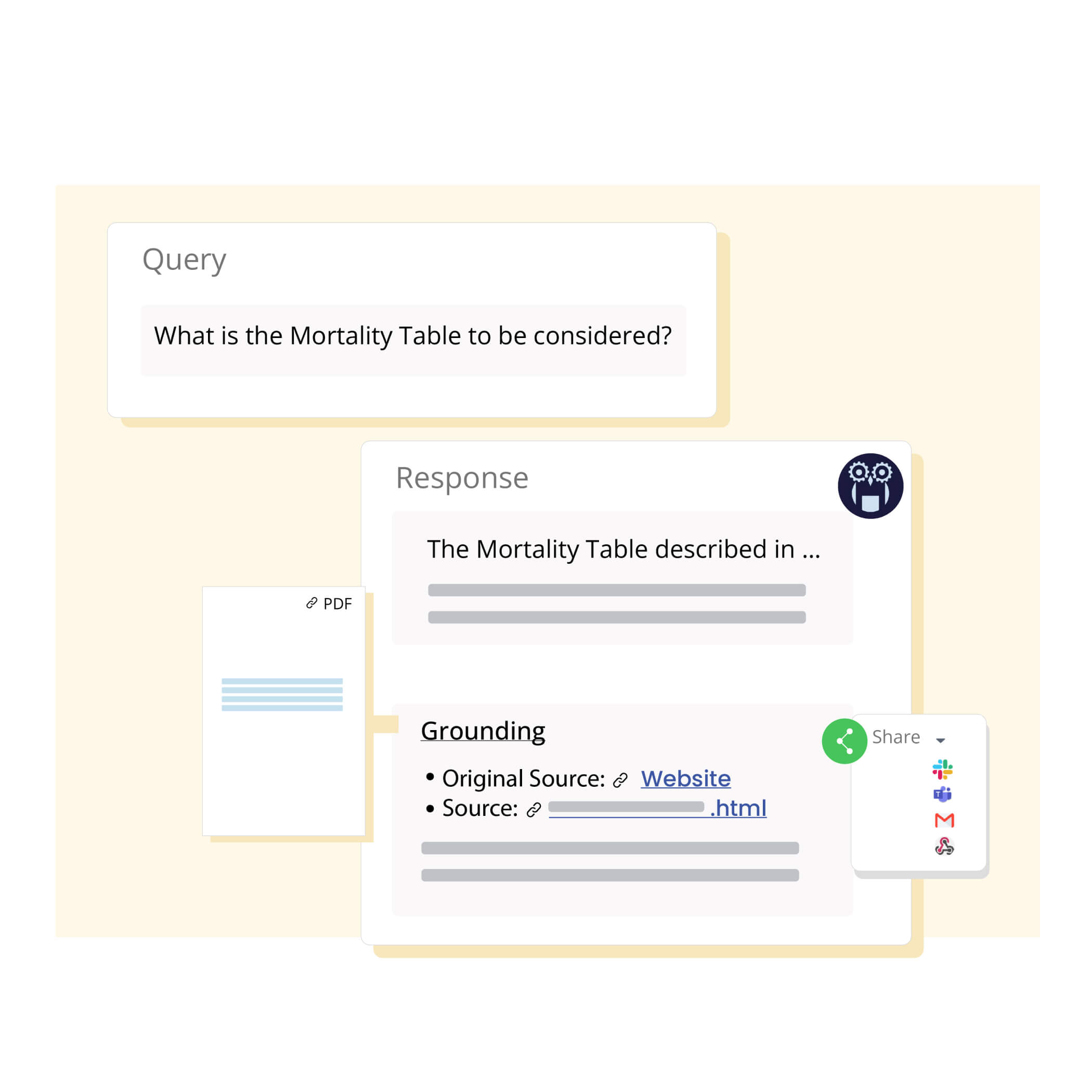
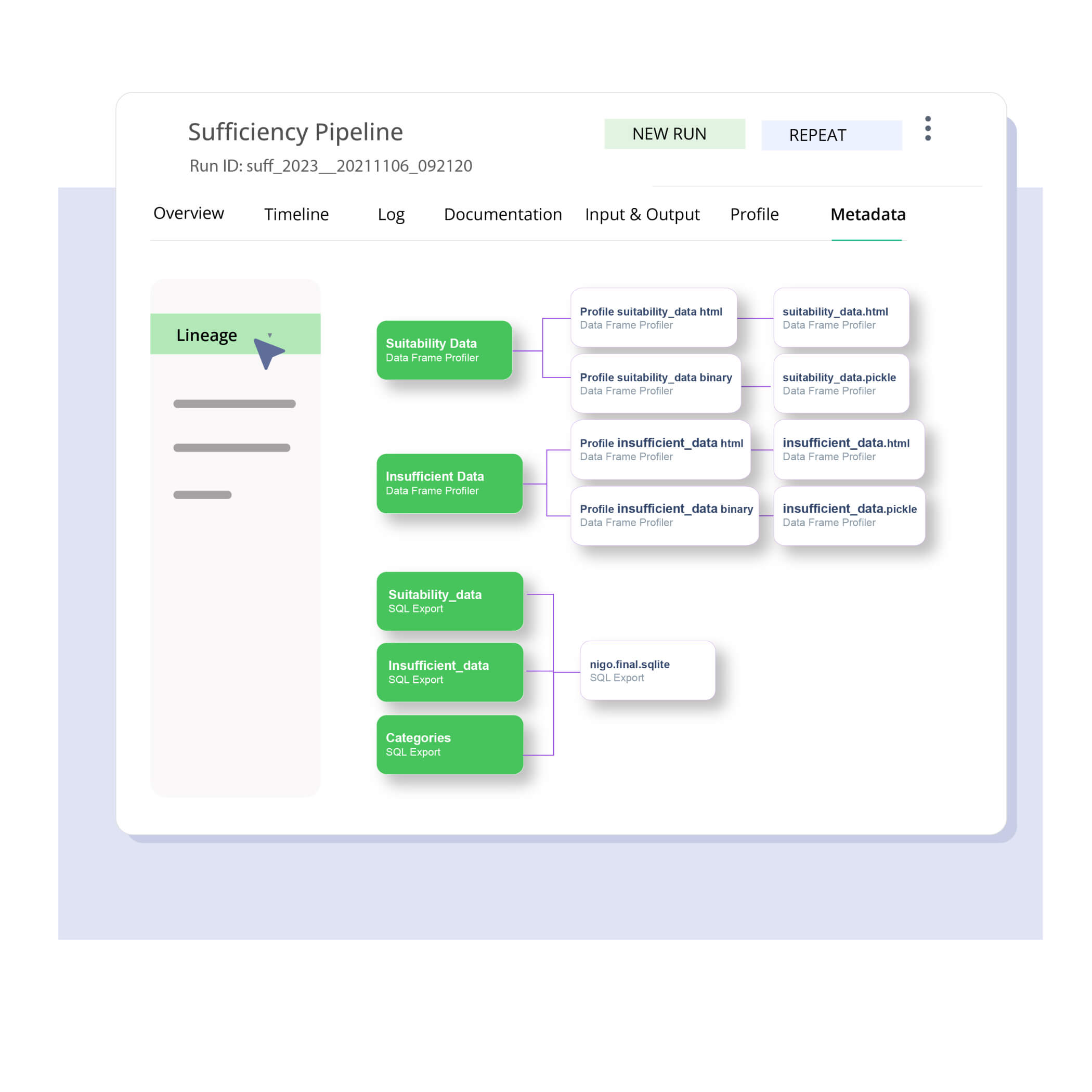
Trace the complete journey of each artifact, including transformations, sources, actions, and pipeline runs to enable high trust and 10X faster troubleshooting.
Effectively handle hallucination! Eliminate misinformation by grounding LLMs with organization-specific knowledge, task-specific context and quality checks, ensuring accurate and relevant results.

Secure
- Secure Hosting Options: Choose between on-premise or virtual private cloud deployment, ensuring your data remains exclusively on your servers for maximum confidentiality.
- SOC2 Compliant: Hasper is architected with security and trust as first-class considerations, and includes features such as code commit tagged pipelines, data anonymization, and GDPR record logging.
- LLM Integrations at every level of privacy: Depending on your privacy policies, Hasper can integrate with a wide range of LLMs, from entirely private to public. Your IP remains yours and is masked to offer an extra layer of security.


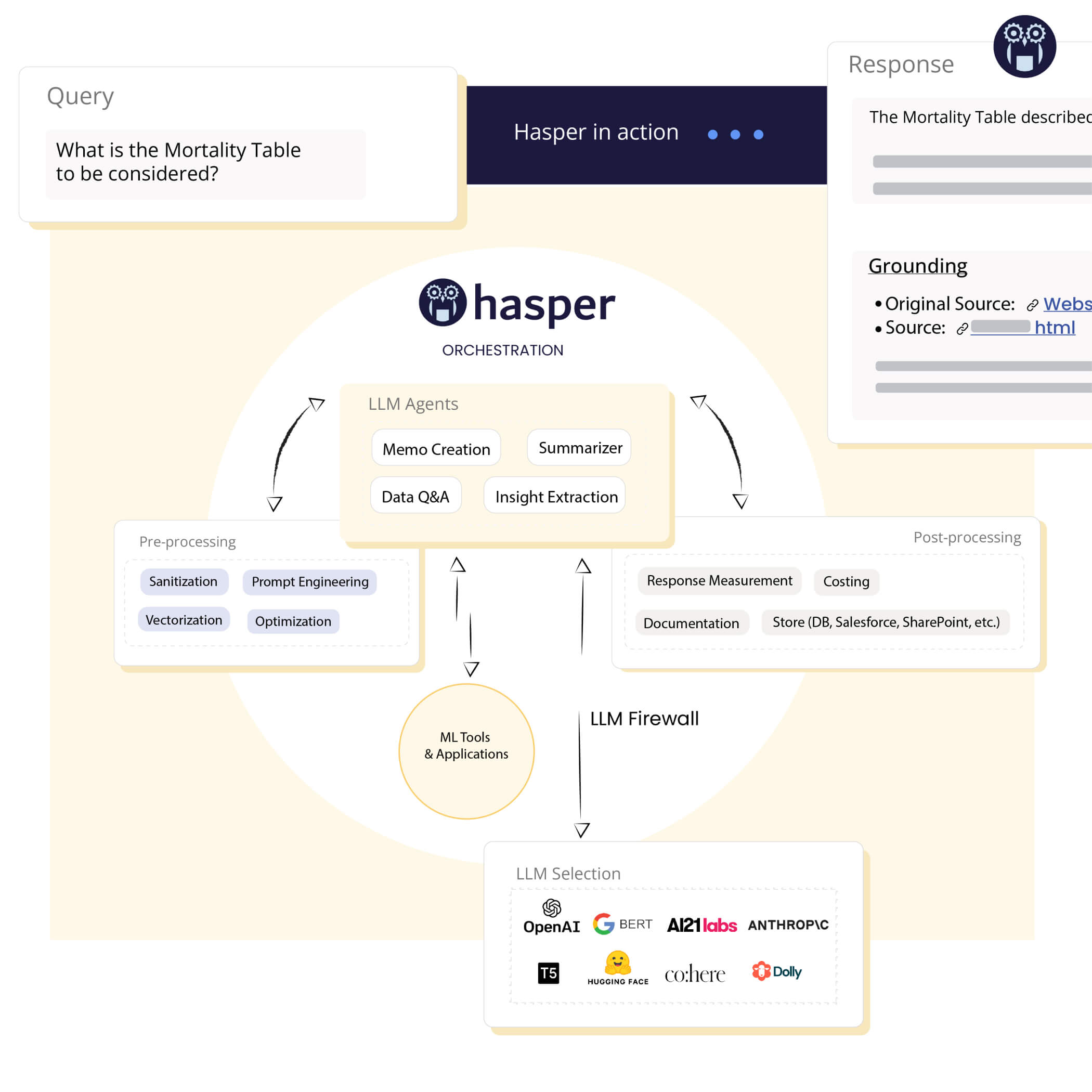
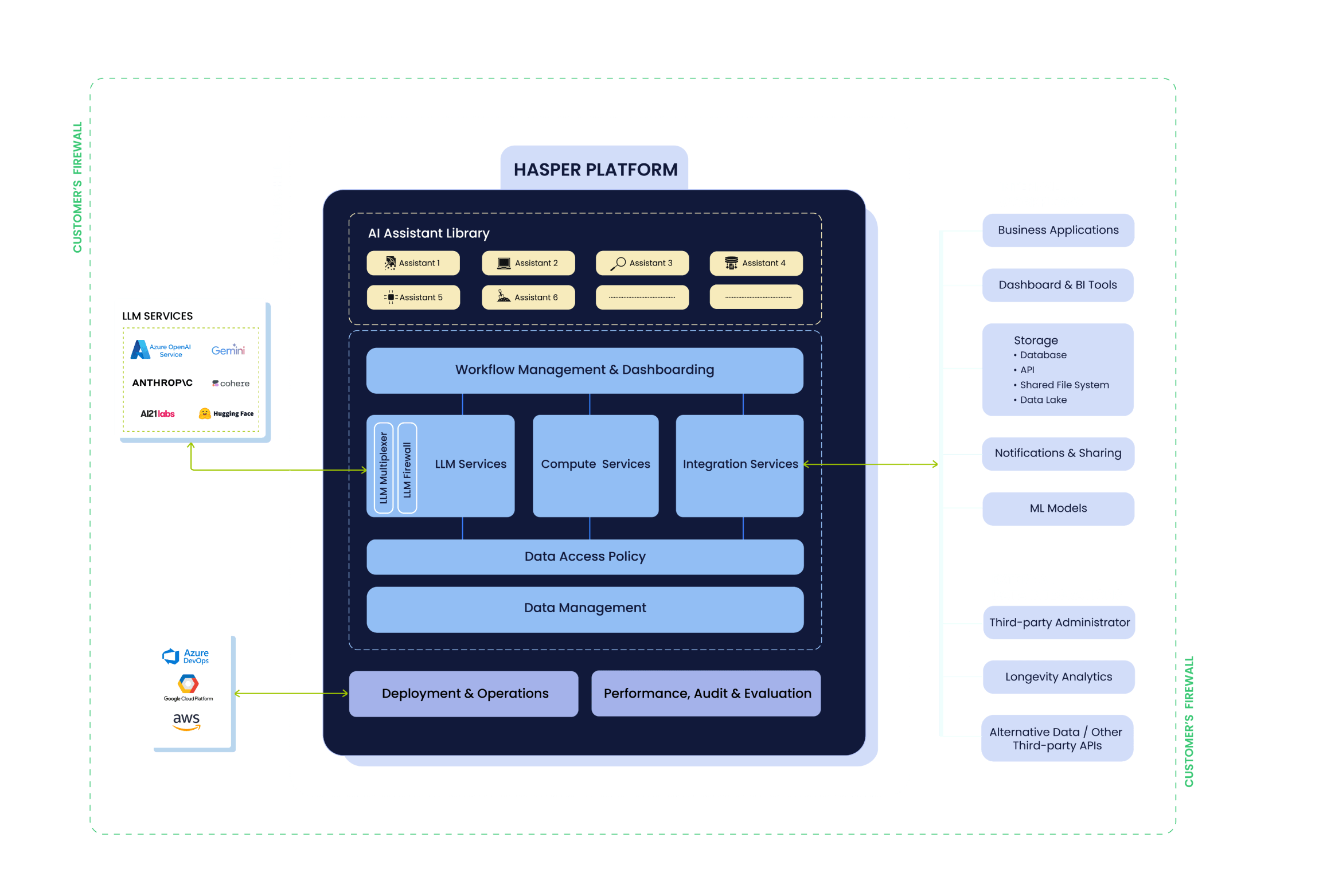
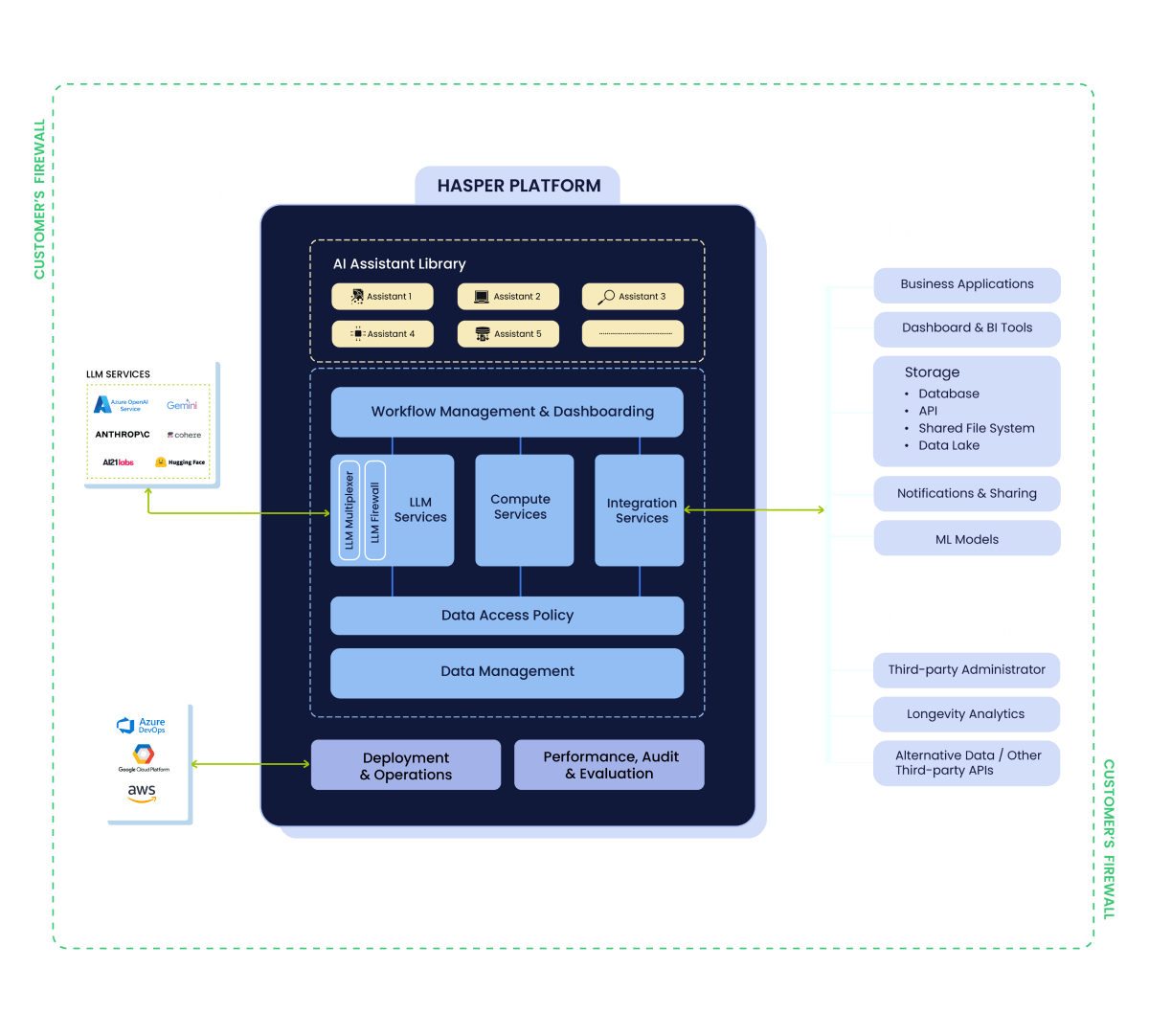
How Hasper Gen AI
Platform Works
- Multiplexer: Automatically select the most suitable LLM based on the complexity and type of use case.
- LLM Firewall: Stay safe against all risks associated with LLMs, like data leakage and prompt injection.
- LLM Task Blades: Solve specific tasks with a high degree of accuracy with purpose-built agents.
- Feature Engineering: Transform raw data into consumption-ready datasets with ease.
- Vectors and pre-processing: Make LLMs fit for enterprise consumption while improving accuracy.
- Data Product Library: A rich repository of advanced analytics data products.
Resources to help you get started

Building AI Assistants: A Comprehensive Guide
For years, a giant mystery confounded the world of medicine. How do proteins fold? The answer, elusive, held the key to life itself. Then, a heroic AI agent – AlphaFold, emerged from DeepMind’s depths. It tackled the giant. And won. AlphaFold produces highly accurate protein structures The implications? Beyond staggering. AlphaFold is just the beginning. […]
Read More
Generative AI in Insurance: Introduction and Key Trends
Picture a scenario where you’ve just been involved in a minor car mishap on your way home. The usual protocol would involve a lengthy wait for an insurance adjuster’s inspection and assessment. However, in this AI-driven scenario, you simply whip out your smartphone, capture some images of the dented bumper, and upload them onto your […]
Read More
Generative AI: A Technical Deep Dive into Security and Privacy Concerns
In a tale as old as time, King Midas yearned for a touch that could metamorphose all to gold. His wish was granted, and the world around him shimmered with the allure of endless wealth. Every object he grazed turned to gold, dazzling yet cold to the touch. The ecstasy of boundless power was intoxicating, […]
Read MoreWant to get started with fast
data-driven decision making today?
Schedule a Demo
Stay updated on the latest and greatest at Scribble Data
Sign up to our newsletter and get exclusive access to our launches and updates