


Let’s say you buy a high-performance sports car, fresh off the production line. It’s capable, versatile, and ready to take on most driving conditions with ease. But what if you have a specific goal in mind – let’s say, winning a championship in off-road rally racing? The sports car, for all its inherent capabilities, would likely fall short in this specialized arena. To enhance its performance on rugged terrains, you’d need to fine-tune it – altering the suspension, changing the tires, or even adjusting the gearbox settings.
In the world of artificial intelligence (AI), large language models (LLMs) are the sports cars. These models, with millions or even billions of parameters, are designed to understand and generate human-like text across a broad spectrum of topics. However, when it comes to specific tasks or domains, performance of LLMs, much like sports cars, could benefit from some fine-tuning.
In this blog, we talk about the concept of fine-tuning LLMs – a process akin to making precise adjustments to our sports car. We will deep-dive into why fine-tuning is needed, delve into the mechanics of how it works, provide a step-by-step guide on the process, and discuss best practices.
Introduction to the world of LLMs
When it comes to Large Language Models (LLMs), the adage ‘knowledge is power’ is particularly apt. Drawing from extensive training on diverse text corpora, LLMs encode a wide-ranging understanding of human language, including linguistic structures, vocabulary, and contextual nuances.
At the heart of an LLM is the transformer, a type of artificial neural network architecture designed to handle the intricate task of processing language. Through the simultaneous processing of information and attention mechanisms, transformers form a sophisticated understanding of context, giving LLMs their impressive language generation abilities.
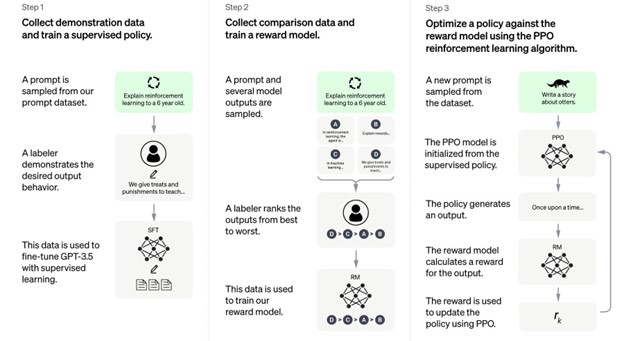
Image source: OPENAI
Some notable examples of LLMs include OpenAI’s GPT-3, Google’s BERT, and Facebook’s LlaMA. BERT revolutionized the field by considering bidirectional context during training, which significantly improved its understanding of sentence structure. LlaMA, building upon BERT, tweaked the training process and dataset size, resulting in a more potent LLM that set new performance benchmarks.
The Need for Fine-Tuning LLMs
Out of the box, LLMs may lack the intricate details and specialized language of specific domains or tasks. For instance, an LLM might be good at generating text on a wide array of topics but may stumble when asked to generate text that adheres to the conventions and style of legal documents or medical reports. This is akin to expecting a general practitioner to perform specialized neurosurgery – while they have broad medical knowledge, they lack the specialized training required for the task.
This is where fine-tuning comes in. Fine-tuning is the process of adjusting the parameters of an already trained model – the LLM in this case – using a smaller, domain-specific dataset. It’s like adding a finishing touch to a nearly complete painting, bringing the details into sharper focus.
To illustrate the power of fine-tuning, let’s consider a real-world example. Researchers at Stanford University fine-tuned several LLMs, for a task called “CommonGen,” which involves generating sentences given a set of common concepts. Out of the box, most models struggled to generate coherent sentences that correctly used all the provided concepts. However, after fine-tuning, the models showed significant improvement, demonstrating an ability to construct relevant and sensible sentences.
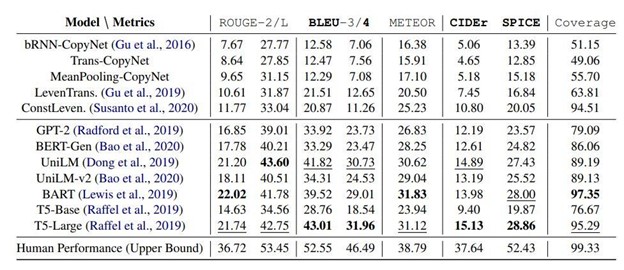
The COMMONGEN test set (v1.1) experimental results from various baseline methods. The first group consists of non-pre-trained models, while the second group includes large pre-trained models that have been fine-tuned. Within each metric, the best models are in bold, and the second-best ones are underlined. Image Source: CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning
Understanding Fine-Tuning in Depth
Fine-tuning is more than just a slight adjustment to an LLM – it’s a crucial step that refines an LLM’s capabilities, adapting it to handle specific tasks or domains with finesse.
The principle behind fine-tuning originates from the broader concept of transfer learning, a common practice in machine learning. Transfer learning, as the name implies, involves transferring knowledge gained from one problem to another, typically related, problem.
Here are the underlying principles and mechanisms that enable the fine-tuning process to work.
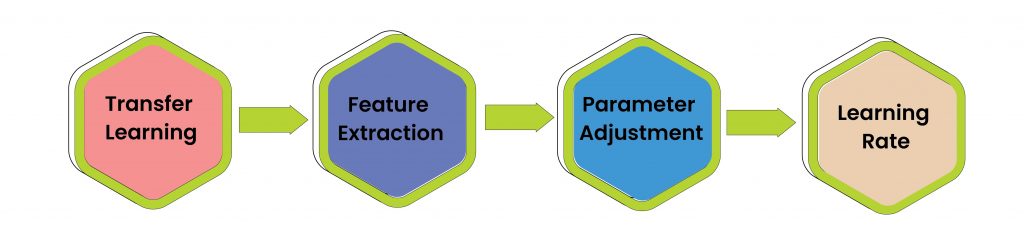
Transfer Learning: At the core of the fine-tuning process is the principle of transfer learning. In the context of machine learning, transfer learning is a method where a pre-trained model is used on a new, similar problem. For example, a model that has been trained on a large corpus of text data can be fine-tuned and used for a specific language task such as sentiment analysis or text generation.
Feature Extraction: When large language models (LLMs) like BERT or GPT-4 are trained, they learn a high-dimensional representation of their input data. These representations, often called embeddings, capture the semantic meanings of words and phrases in their training data. While fine-tuning these models, researchers leverage these pre-learned representations and adjust them to better suit the specific task.
Parameter Adjustment: During the fine-tuning process, the model’s parameters (weights and biases) are slightly adjusted, or “fine-tuned,” on a new task-specific dataset. This is usually a much smaller dataset that wouldn’t be sufficient to train a model from scratch, but in combination with the pre-trained model, it’s enough to teach the model to perform a new task. The model keeps its ability to understand language from its original training, while also learning to understand the specifics of the new task.
Impact of Learning Rates: The learning rate in fine-tuning is crucial. It refers to a hyperparameter that determines the amount by which the weights of a neural network model are updated during training. Essentially, it controls how quickly or slowly a machine learning model “learns.”
It must be chosen carefully, as a too-large learning rate might cause the model to forget its original training (catastrophic forgetting), while a too-small learning rate might adversely affect the model’s performance significantly.
The Process of Fine-Tuning LLMs
Fine-tuning an LLM involves more than adjusting a few parameters. It’s a meticulous process requiring careful planning, a clear understanding of the task at hand, and an informed approach to model training. Let’s explore this process in detail:

Step 1: Identify the Task and Gather the Relevant Dataset
The first step towards fine-tuning is to clearly define the task that the LLM should specialize in. This could range from sentiment analysis or text summarization to generating domain-specific text, like medical reports or legal documents.
Once the task is identified, the next step is to gather a relevant dataset for fine-tuning. This dataset should reflect the nature of the task at hand and include enough examples to help the LLM learn the task’s intricacies. For example, if the task is to generate medical reports, the dataset should consist of authentic medical reports. Quality and diversity of data are key factors to consider when collecting the dataset.
Step 2: Preprocess the Dataset
Before feeding the dataset into the LLM, it should be preprocessed according to the requirements of the LLM. This could include tasks like tokenizing the text, splitting the data into training and validation sets, and converting it into a format that the LLM can understand.
Step 3: Initialize the LLM with Pre-Trained Weights
The next step is to load the LLM with its pre-trained weights. These weights represent the knowledge that the LLM has gained from its initial training phase and serve as a strong starting point for fine-tuning.
Step 4: Fine-Tune the LLM
Now comes the actual fine-tuning process. The LLM is trained on the task-specific dataset, adjusting its weights and biases in response to the new data. This is typically done using a smaller learning rate than the original pre-training to ensure that the model doesn’t deviate too far from its initial knowledge.
Step 5: Evaluate and Iterate
Once the fine-tuning process is complete, the LLM’s performance should be evaluated on a validation set. This helps to gauge how well the fine-tuning has worked and whether the LLM is now capable of performing the specific task effectively. If the performance isn’t up to the mark, adjustments can be made, and the fine-tuning process can be repeated.
Common Challenges and Tools
Fine-tuning an LLM isn’t always a straightforward process – it can come with its own set of challenges. These might include overfitting, where the LLM performs well on the training data but fails to generalize to unseen data, or catastrophic forgetting, where the LLM loses its initial pre-training knowledge.
To navigate these challenges, a variety of tools and resources are available. Libraries like Hugging Face’s Transformers provide pre-trained models and utilities that simplify the fine-tuning process. Similarly, using techniques like early stopping, weight decay, and learning rate scheduling can help mitigate overfitting.
In essence, the process of fine-tuning involves iteratively refining the LLM to perform a specific task effectively, using a carefully chosen relevant dataset.
Now, let’s delve into some best practices that can further guide this fine-tuning process.
Best Practices for Fine-Tuning LLMs
Fine-tuning LLMs can be both an art and a science, requiring a balance between empirical experience and theoretical knowledge. While the specifics can vary depending on the task and the model, some general best practices can guide the process and enhance the results.
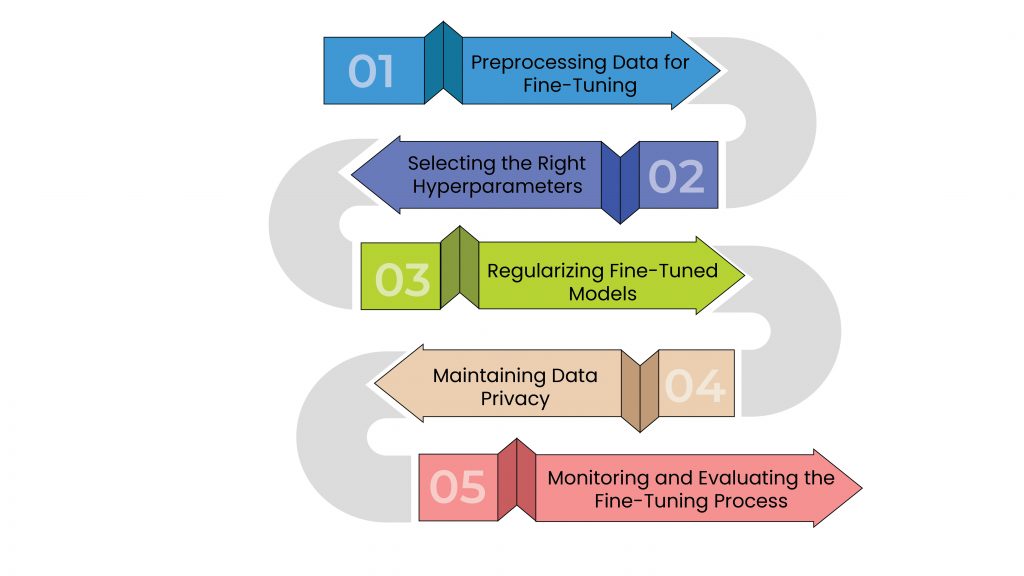
Preprocessing Data for Fine-Tuning: The saying “garbage in, garbage out” holds true in machine learning. The quality of your input data can significantly impact the performance of the fine-tuned model. Therefore, ensuring your data is clean, diverse, and representative of the task at hand is critical. Techniques like tokenization, lemmatization, or handling of out-of-vocabulary words, can help refine your input data, making it more conducive for the LLM.
Selecting the Right Hyperparameters: Hyperparameters like learning rate, batch size, and the number of training epochs play a vital role in fine-tuning. Selecting the right values can be challenging, often requiring a fair bit of trial and error. Guidelines and pre-established practices can serve as a starting point but don’t shy away from experimentation.
Regularizing Fine-Tuned Models: Regularization techniques can be invaluable in preventing overfitting and ensuring your model generalizes well to unseen data. Techniques such as dropout, weight decay, and early stopping can help ensure the model doesn’t fit too closely to the training data.
Maintaining Data Privacy: While fine-tuning your LLM, ensuring the privacy of your data is crucial, especially if you’re dealing with sensitive information. This is where techniques like differential privacy (a mathematical technique used to maximize the accuracy of queries from statistical databases while minimizing the chances of identifying its entries) come into play. In addition, by adding a carefully calculated amount of noise to your data during the fine-tuning process, you can prevent the possibility of sensitive information being reverse-engineered from your model, thereby preserving data privacy. However, it’s a delicate balance to strike—adding too much noise can adversely affect model performance. Therefore, differential privacy should be implemented with care and expertise.
Monitoring and Evaluating the Fine-Tuning Process: Continuously monitoring the model’s performance during fine-tuning can help identify issues early and guide adjustments. Utilize metrics relevant to your task to evaluate the model’s performance. If the model’s validation performance plateaus or starts to deteriorate, consider adjusting the learning rate or employing early stopping.
Case Studies of Successful Fine-Tuning
Now that we’ve gone through the theory and the best practices of fine-tuning, let’s shift gears and explore some real-world applications where fine-tuning LLMs has led to remarkable results.
| Case Study 1: Fine-Tuning GPT-3 for Legal Document Analysis
Legal documents, filled with complex language and jargon, present a significant challenge. However, companies like Lawgeex have been able to successfully fine-tune LLMs using a specific corpus of legal texts, creating a model that could quickly and accurately analyze and generate summaries of legal documents. This application significantly reduces the time attorneys spent reviewing documents, allowing them to focus more on strategic tasks. It’s a prime example of how fine-tuning can take a generalist LLM and transform it into a specialist tool. and their corresponding audience ratings, the team was able to create a model that could predict audience sentiment with high accuracy. This application shows how fine-tuning can equip an LLM to accurately understand and interpret nuanced human emotions. |
| Case Study 2: Fine-Tuning LLMs for Sentiment Analysis
Sentiment analysis is a common task in natural language processing, often used to gauge public opinion on social media or review sites. In 2014, a research team fine-tuned an LLM to create a sentiment analysis tool for the film review website, Rotten Tomatoes. By fine-tuning the model with a dataset of movie reviews and their corresponding audience ratings, the team was able to create a model that could predict audience sentiment with high accuracy. This application shows how fine-tuning can equip an LLM to accurately understand and interpret nuanced human emotions. |
| Case Study 3: Fine-Tuning BERT for Spanish Language Processing
While LLMs are typically trained on a mix of languages, they can struggle with text in languages other than English due to the disproportionate representation in the training data. However, fine-tuning can address this limitation. A group of researchers fine-tuned BERT for Spanish language processing. Using a comprehensive corpus of Spanish text, the team was able to fine-tune BERT to understand and generate Spanish text effectively. |
The Future of Fine-Tuning LLMs
As we race towards an AI-centric future, the fine-tuning of LLMs continues to be a rapidly evolving field, with numerous fascinating research developments and industry applications on the horizon.
Current Research and Advancements in Fine-Tuning Methods
Many researchers are experimenting with alternative approaches to fine-tuning to enhance model performance and efficiency. For instance, research is being done into ‘few-shot learning,‘ where an LLM is fine-tuned to learn from a very small number of examples. This could drastically reduce the amount of training data required and potentially even enable the model to generalize better to unseen data.
Another intriguing development is the concept of ‘intermediate-task fine-tuning’ where the model is first fine-tuned on an intermediate task before being fine-tuned on the final task. This staged fine-tuning process can help to narrow down the model’s knowledge gradually, improving its performance on the final task.
The Impact of These Advancements on Industry and Research
These advancements hold immense promise for a broad range of industries. For instance, in healthcare, models fine-tuned to understand medical language and literature could aid in drug discovery or disease diagnosis. In finance, LLMs fine-tuned to understand economic trends and financial reports could help in market prediction. In education, LLMs could be fine-tuned to serve as personalized tutors, adapting to each student’s learning style.
As models continue to grow larger and more powerful, effective fine-tuning will become even more essential to leverage these models’ capabilities fully. It’s conceivable that we’ll see more fine-tuned models in a broad array of specialized tasks and languages, further democratizing AI and making it accessible to even more people and industries.
The road to perfect fine-tuning is an ongoing journey, paved with constant learning, experimentation, and innovation. As advancements continue in AI research, and as LLMs become even more powerful and sophisticated, the importance and impact of fine-tuning will only grow.
At Scribble, we are bridging the gap between LLMs and enterprise analytics. If you want to leverage generative AI and machine learning to tackle advanced analytics challenges, schedule a customized demo with us today.
Do check out Carver Agents’ RegWatch – our new AI solution for real-time contextual regulatory risk intelligence, built for risk and strategy executives. Think of it as agentized mid-market LexisNexis. Visit https://carveragents.ai/.