

Imagine walking into the Library of Alexandria, one of the largest and most important libraries of the ancient world, filled with countless scrolls and books representing the accumulated knowledge of the entire human race.
It’s like being transported into a world of endless learning, where you could spend entire lifetimes poring over the insights of the greats in every field – from astronomy to mathematics to chemistry.
Now imagine being able to wield the power of the Library of Alexandria at your fingertips. It is a mind-boggling achievement that would appear absolutely magical to someone who lived even 100 years ago.
That’s the power of Large Language Models (LLMs), the modern equivalent of this legendary library. They can answer questions, summarize entire books, translate and contextualize text from multiple languages, and solve complex equations.
They’re also at your beck and call when you need some motivational poetry on a Monday morning.
What is a Large Language Model?
A large language model, or LLM, is a neural network with billions of parameters trained on vast amounts of unlabeled text using self-supervised or semi-supervised learning. These general-purpose models are capable of performing a wide variety of tasks, from sentiment analysis to mathematical reasoning.
Despite being trained on simple tasks like predicting the next word in a sentence, LLMs can capture much of the structure and meaning of human language. They also have a remarkable amount of general knowledge about the world and can “memorize” an enormous number of facts during training. Think of LLMs as giant, flexible brains that can be taught to do almost anything, provided they have access to enough data and processing power. So, the next time you ask ChatGPT a question, just remember: you’re interacting with one of the most impressive pieces of AI technology in existence.
History of Large Language Models
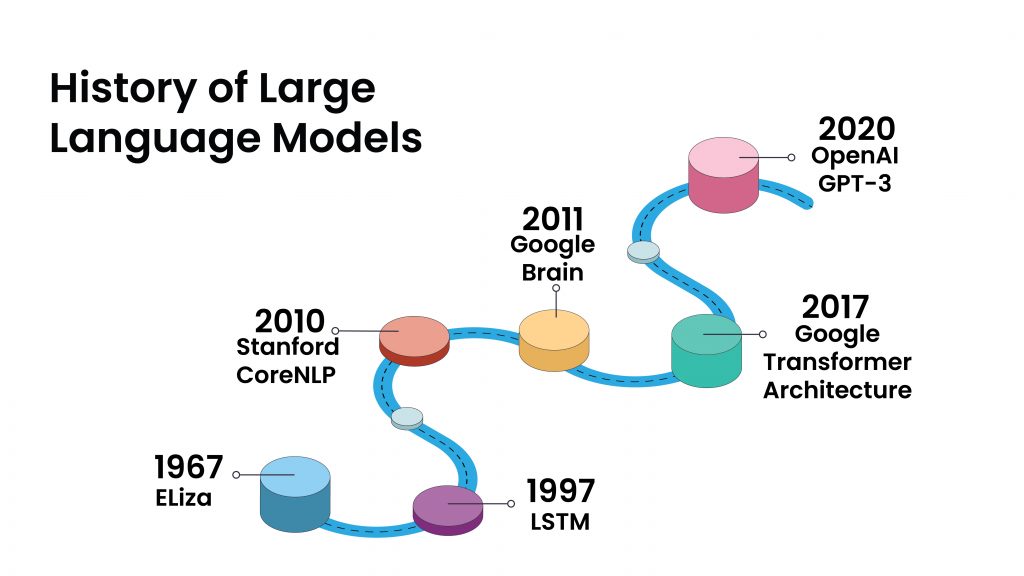
LLMs have a fascinating history that dates back to the 1960s with the creation of the first-ever chatbot, Eliza. Designed by MIT researcher Joseph Weizenbaum, Eliza was a simple program that used pattern recognition to simulate human conversation by turning the user’s input into a question and generating a response based on a set of pre-defined rules. Though Eliza was far from perfect, it marked the beginning of research into natural language processing (NLP) and the development of more sophisticated LLMs.
Over the years, several significant innovations have propelled the field of LLMs forward. One such innovation was the introduction of Long Short-Term Memory (LSTM) networks in 1997, which allowed for the creation of deeper and more complex neural networks capable of handling more significant amounts of data. Another pivotal moment came with Stanford’s CoreNLP suite, which was introduced in 2010. The suite provided a set of tools and algorithms that helped researchers tackle complex NLP tasks such as sentiment analysis and named entity recognition.
In 2011, Google Brain was launched, providing researchers with access to powerful computing resources and data sets along with advanced features such as word embeddings, allowing NLP systems to better understand the context of words. Google Brain’s work paved the way for massive advancements in the field, such as the introduction of Transformer models in 2017. The transformer architecture enabled the creation of larger and more sophisticated LLMs such as OpenAI’s GPT-3 (Generative Pre-Trained Transformer) which served as the foundation for ChatGPT and a legion of other incredible AI-driven applications.
In recent years, solutions such as Hugging Face and BARD have also contributed significantly to the advancement of LLMs by creating user-friendly frameworks and tools that enable researchers and developers to build their own LLMs.
Types of Large Language Models
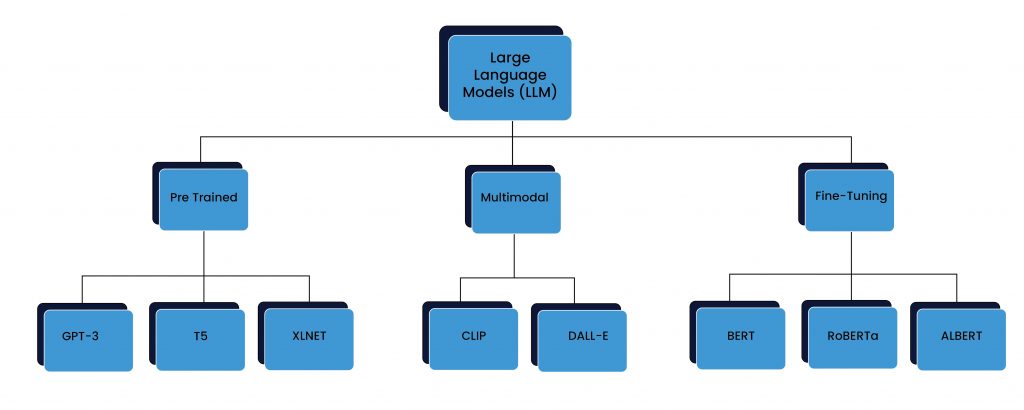
Large Language Models (LLMs) can be broadly classified into three types – pre-training models, fine-tuning models, and multimodal models.
- Pre-training models like GPT-3/GPT-3.5, T5, and XLNet are trained on vast amounts of data, allowing them to learn a wide range of language patterns and structures. These models excel at generating coherent and grammatically correct text on a variety of topics. They are used as a starting point for further training and fine-tuning for specific tasks.
- Fine-tuning models like BERT, RoBERTa, and ALBERT are pre-trained on a large dataset and then fine-tuned on a smaller dataset for a specific task. These models are highly effective for tasks like sentiment analysis, question-answering, and text classification. They are often used in industrial applications where there is a need for task-specific language models.
- Multimodal models like CLIP and DALL-E combine text with other modalities like images or video to create more robust language models. These models can understand the relationships between images and text, allowing them to generate text descriptions of images or even generate images from textual descriptions.
Each type of LLM has its unique strengths and weaknesses, and the choice of which one to use depends on the specific use case.
Applications of Large Language Models
Large Language Models (LLMs) have demonstrated remarkable performance in a wide range of natural language processing (NLP) tasks. In this section, we will explore some of the most significant applications of LLMs.
- Evolving Conversational AI: LLMs have shown impressive results in conversational AI, where they can generate responses that are not only contextually relevant but also maintain coherence throughout the dialogue. The widespread adoption of chatbots and virtual assistants is a testament to the growing use of LLMs.
A study by Google researchers in 2020 found that their LLM, Meena, outperformed all other dialogue agents in a human evaluation of sensibleness and response quality, achieving a score of 79% compared to the next-best agent’s score of 56%. Meena was trained with 2.6 billion parameters on a massive 341 GB dataset of social media conversations and can engage in a wide range of topics, making it an impressive example of how LLMs are pushing the boundaries of conversational AI. LLMs are also being used to improve the accuracy of speech recognition systems, which are essential for many conversational AI applications.
- Textual Content Creation: LLMs have proven to be useful in generating text in various forms, such as news articles, product descriptions, and even creative writing. GPT-3, for example, has shown impressive results in generating coherent and creative text. The technology has the potential to revolutionize content creation and reduce the time and resources required to produce quality content.
- Understanding sentiments within the text: Sentiment analysis is a technique used to identify and extract subjective information from text, such as emotions, opinions, and attitudes. LLMs have been shown to perform well in sentiment analysis tasks, with applications in customer feedback analysis, brand monitoring, and social media analysis.
In 2020, OpenAI tested GPT-3 on a dataset of tweets related to the COVID-19 pandemic. The model was able to accurately identify the sentiment of each tweet, whether it was positive, negative, or neutral. This kind of analysis can help public health officials understand how people are feeling about the pandemic and respond accordingly. In 2022, researchers from Google and The Ohio State University published a paper that showed that LLMs were remarkably accurate at deriving insights about financial markets by analyzing Twitter and Reddit threads.
- Efficient Machine Translation: The traditional approach to machine translation involved rule-based systems that required a lot of human input to develop complex sets of linguistic rules. But with the advent of LLMs, translation systems are becoming more efficient and accurate.
One of the most remarkable examples of LLMs being used for translation is Google Translate. Google has been using neural machine translation (NMT) models powered by LLMs since 2016. Google Translate’s system has proven to be remarkably effective, producing close to human quality translations for over 100 languages. By breaking down these language barriers, LLMs are making it possible for humans all over the world to share knowledge and communicate with each other in a way that was previously impossible.
ChatGPT’s Code Interpreter Plugin represents yet another step towards simplifying human-to-machine communication by making it possible for developers and non-coders alike to build applications by offering instructions in simple English.
The Limitations of Current-Gen LLMs
- Ethical and privacy concerns: Large datasets may contain sensitive information that can be used to identify individuals or groups, and currently, there are very few regulatory frameworks to ensure that this information is handled ethically.
For example, OpenAI’s GPT-3 was trained on billions of words from various sources including Common Crawl, WebText, books, and Wikipedia, raising ethical concerns over the fair use of intellectual property by authors and researchers. Obtaining explicit permission from copyright holders, especially in fine-tuning models, is necessary to avoid legal issues. Obtaining consent for the use of data from deceased individuals such as older authors poses an additional challenge as permission cannot be obtained.
- Biases and fairness problems: Another issue with large language models is the potential for cultural and regional biases to be amplified. Because these models are trained on large amounts of text data from the internet, they may inadvertently learn and reinforce biases present in that data, such as gender, racial, or geographic biases.
This phenomenon was demonstrated in a 2016 study which showed that popular word embedding models trained on large text datasets were capable of encoding gender stereotypes, such as associating words like “programmer” and “engineer” more strongly with men than women. These biases have real-world consequences, particularly in applications such as hiring or lending decisions, where biased outputs from a language model could lead to unfair treatment.
- Carbon footprints and massive computational costs: LLMs require vast amounts of computational power to train, which can have a significant impact on energy consumption and carbon emissions. In addition, training and deploying LLMs can be prohibitively expensive for many organizations, particularly smaller companies, or academic institutions. It is estimated that training OpenAi’s GPT-3 model from scratch would cost somewhere in the neighborhood of $4.6 million in cloud computing resources alone, not to mention the carbon footprint of such a massive endeavor.
What Does the Future of Large Language Models Look Like?
Even with the exponential rate of advancements in the field of AI, we are still quite far away from the end state or the “event horizon” of LLMs. While ChatGPT is undoubtedly impressive, it only represents an intermediary step to what’s coming next. The future of LLMs is fluid and unpredictable, but here are some trends that we see shaping the trajectory of these models in the years to come.
- Autonomous models that generate training data to improve their performance: Today’s LLMs use the vast cumulative reserves of written knowledge (Wikipedia, articles, books) to train themselves. But what if these models were to utilize all of their training to produce new content and then use it as additional training data to improve themselves? When you consider that we may soon run out of input data for LLMs, auto-generation of training content is an approach that several researchers are already working towards.
Recently, Google built an LLM that generates its own questions and answers, filters the output for the highest quality content, and then fine-tunes itself on the curated responses. Another study focused on instruction fine-tuning, a core LLM method, and built a model that generates its own natural language instructions, then fine-tunes itself on those instructions. This method improved the performance of the GPT-3 model by 33%, nearly matching the performance of OpenAI’s own instruction-tuned model. Additionally, a related study found that large language models which first recite what they know about a topic before responding provide more accurate and sophisticated answers, much like how humans take time to reflect before sharing their perspectives in a conversation.
- Models that can validate their own information: The current iteration of LLMs can never fully replace something like a Google search. While these models are incredibly powerful, they regularly generate misleading or inaccurate information and present it as facts. For an LLM-based search engine to truly thrive, even a 99% accuracy rate is simply not good enough.
To remedy this, LLMs can increase transparency and trust by providing references to the source(s) of information they retrieve. This allows users to audit information for reliability. Key early models in this area include Google’s REALM and Facebook’s RAG. With the increase in the use of conversational LLMs, researchers are working feverishly to build more reliable models. OpenAI’s WebGPT, a fine-tuned version of its GPT model, can browse the internet using Bing to provide more accurate and in-depth responses with citations that can be audited by humans.
- Rise of Sparse Expert Models: The most popular LLMs of today – GPT-3, LaMDA, Megatron-Turing, and others – all share the same basic structure. They are dense, self-supervised, pre-trained models based on the transformer architecture. In this context, “dense” means that the model uses every single one of its parameters for each query. If you ask GPT-3 something, the model uses all 175 billion of its parameters to provide an answer.
But momentum is building behind a different approach to LLM architectures – sparse expert models. Simply put, sparse expert models are built on the idea that only the parameters that are relevant to a query need to be activated to produce the output. As a result, these models can be much larger, more complex, and yet significantly less resource-heavy than our current dense models. Google’s GLaM model, for example, is 7x the size of GPT-3, requires significantly less energy and computation for training, and performs better than GPT-3 in a variety of language tasks.
The development of LLMs is a rapidly evolving field with new breakthroughs and discoveries emerging all the time. While it is difficult to predict exactly where this technology will lead us, one thing is clear: LLMs have the potential to revolutionize the way we communicate and work with language in ways that we can’t yet imagine.
Do check out Carver Agents’ RegWatch – our new AI solution for real-time contextual regulatory risk intelligence, built for risk and strategy executives. Think of it as agentized mid-market LexisNexis. Visit https://carveragents.ai/.