


Let’s assume you want to leverage data to improve one of your processes, such as partner benchmarking. Even though it’s one of your top priorities for the year, you have limited resources to spend on partner data collection, segregation, and overall data preparation to do any sort of analysis. And even if you find a way around it, there’s a high probability that this approach will have a short shelf life due to an evolving business environment, as well as an opportunity cost owing to your data science team’s limited bandwidth – which could have easily been utilized on use cases with a significantly higher business impact.
What do you do in such a situation, where you have a process that needs improvement, but have limited resources?
Venkata Pingali, Co-Founder, and CEO at Scribble Data, recently spoke about this and other similar problem statements that can be addressed using a Sub-ML approach at Featurestore.org’s meetup with Jim Dowling, CEO of Logical Clocks and Associate Professor at KTH Royal Institute of Technology.

We’ve listed some of the key takeaways and actionable insights from the meetup here, but don’t forget to watch the complete on-demand webinar here to capture every minute of the insightful conversation!
In this meetup, Venkata spoke about
-
Sub-ML and its significance from a system, data science, and business perspective.
-
What it means to design a feature store for Sub-ML; and
-
Observations and predictions about where we see Sub-ML headed
Understanding Sub ML from a system standpoint,
data science as well as a business standpoint
Every complicated data science use case involves the application of feature engineering and models. We find that every organization has three buckets or categories of use cases it needs to choose from, based on their business impact:
-
“Priority” when the number of use cases is low, but the impact is high. For example, a search function for an eCommerce company is usually a priority project where many resources are deployed with a complex infrastructure.
-
“Maybe,” for when the impact is medium, but the number of use cases is higher. These are typically decision support problems such as fraud detection in a marketplace. These problems tend to be second or third on the list of priorities for an organization.
-
“Not Important,” when the use cases have zero to minimal impact on the business, it is hard to justify the ROI.
According to Venkata, of all the data science use cases under consideration for an organization, 70% fall into the “Maybe” bucket, and 30% in the “Priority” bucket. And the remaining projects that fall under the “Not important” bucket are not worth considering from a cost structure standpoint.
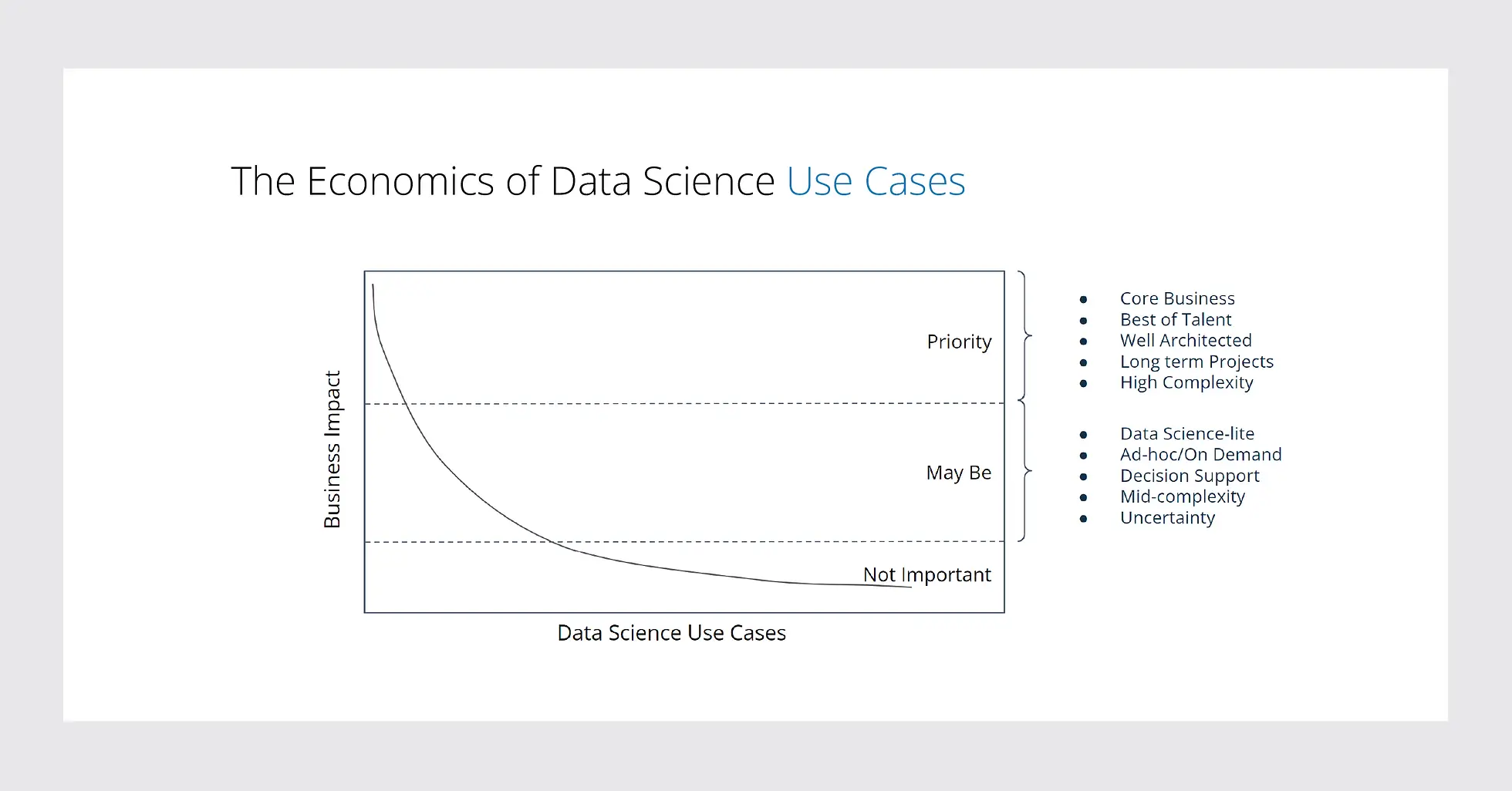
The “not important” bucket looks like decision support problems, covering 70% of the products. What is exciting today is how these buckets have evolved over the past few years. The middle bucket of “Maybe” use cases has increased significantly over the past three years, showing an almost 50% growth, with a lot of spreadsheet-based problem statements slowly scaling and graduating to this bucket. This has made it one of the fastest-growing subspace of use-cases that we call Sub-ML.
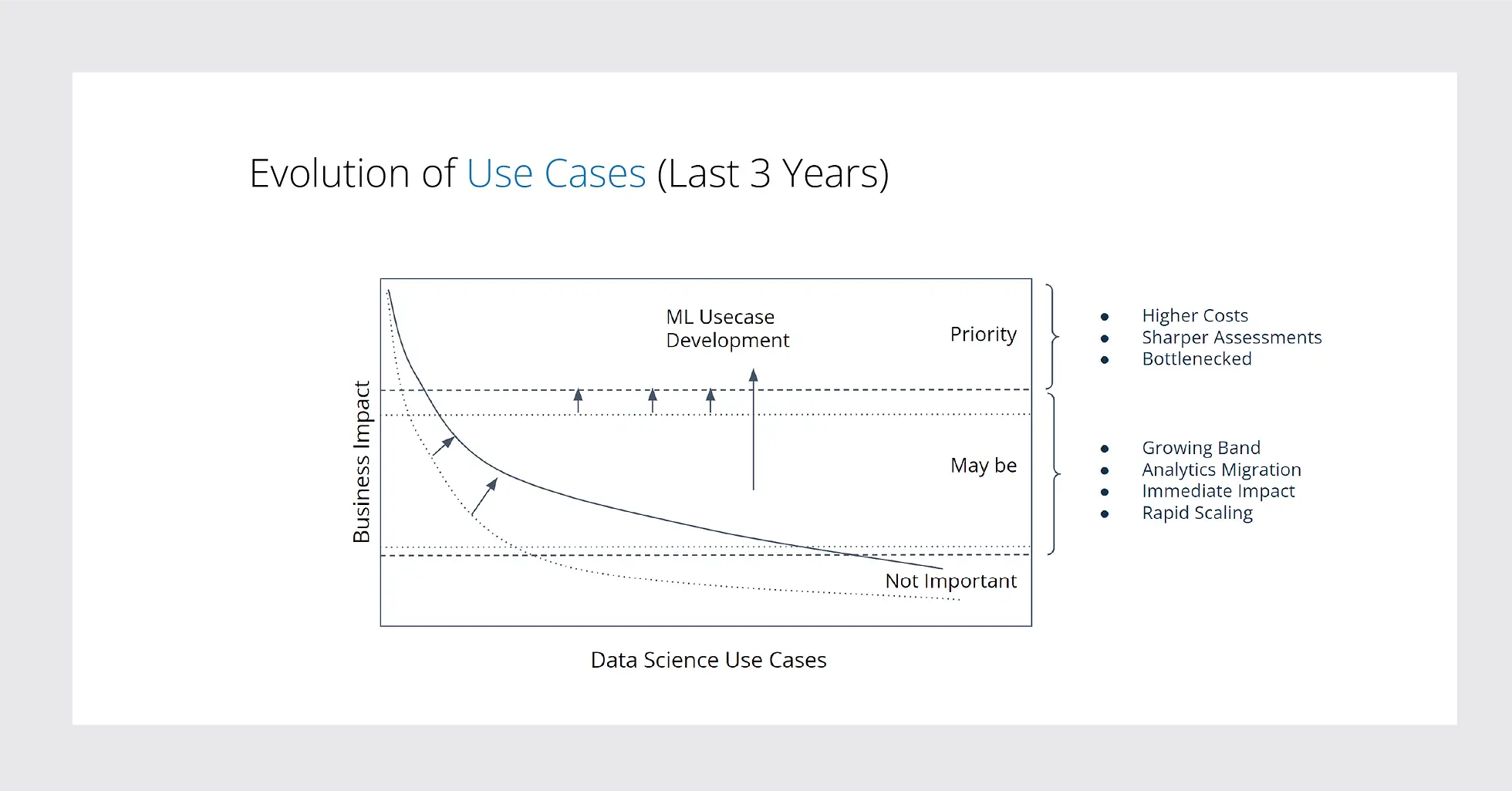
Venkata mentioned, “The interesting thing is that the basic data science lifecycle seems to apply to all of these Sub-ML use cases. You still have a combination of feature engineering and modeling, and it’s also a continuous process with all the checks and balances, except that it is simpler than what we can think of as Big-ML, which consumes a lot of data”. Venkata further went on to explain Sub-ML use cases with the following use cases.

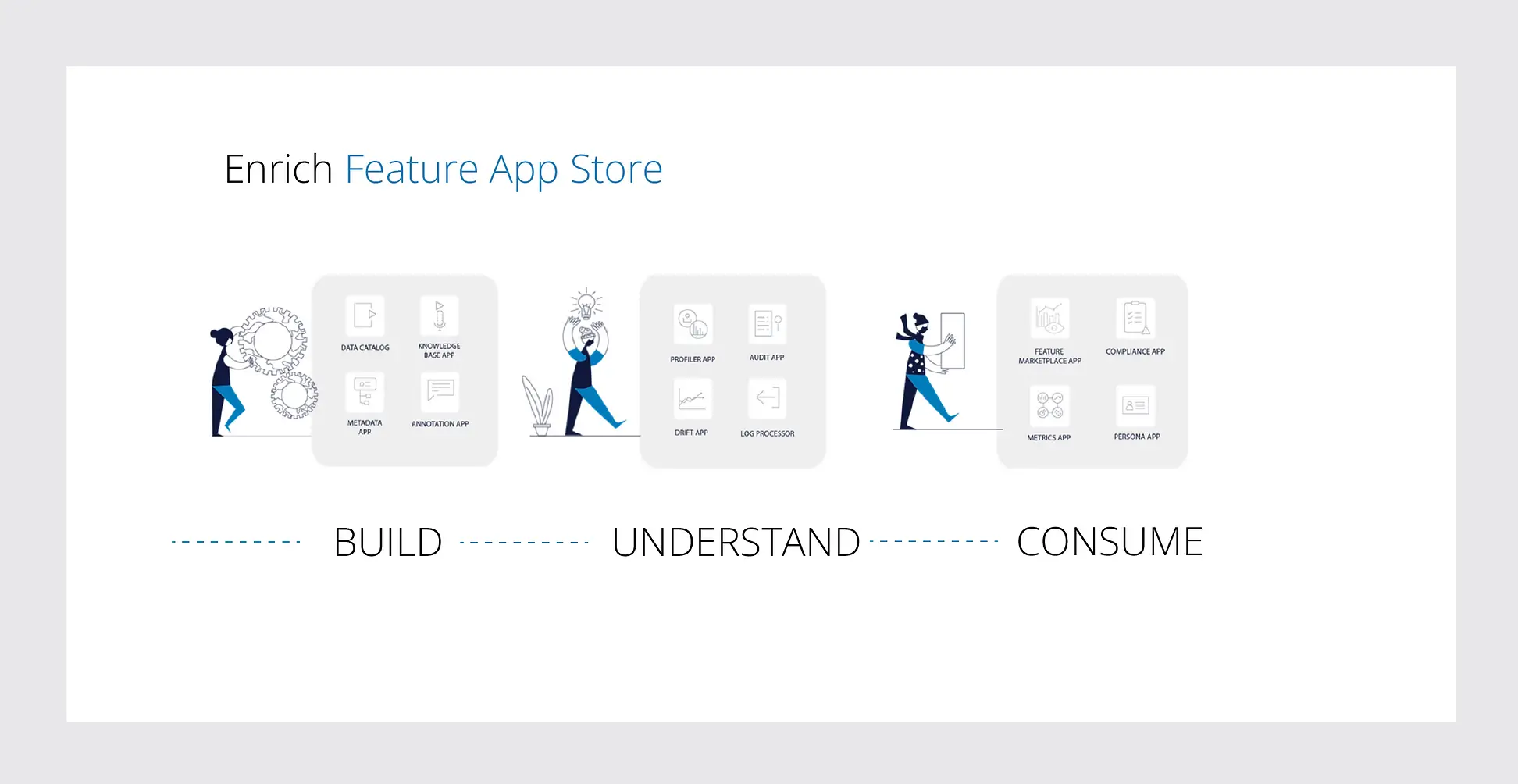
Scribble Data’s modular Feature Store, Enrich takes care of business’s ML and Sub-ML use cases. The Enrich Feature App store builds and discovers prepared data assets & features, enables data practitioners to understand the context of data assets & features, and consume data assets and features across teams – internal and external, technical and non-technical.
Designing a Feature Store for Sub-ML
Even though the lifecycle of both Sub-ML and Big-ML is similar, they are vastly different in design. From the number of use cases that can be managed in parallel to the user skill sets and the time taken for productionization – from days to weeks in the case of Sub-ML to many months in the case of Big-ML.
In order to highlight this difference, Venkata added, “Traditional Machine Learning problems have open-ended timelines because of the sheer scale and complexity of data. We’ve seen that each iteration of a use case takes months– 6-12 months is not unusual. Whereas, in the case of partner benchmarking-like Sub-ML use cases, we operate on extremely tight timelines. This takes anywhere from 5 days for an iteration, with the completed output within a 3-4 week time frame.”

Due to their lack of “Priority” status, organizations cannot spare separate data scientists and business analysts teams for use cases that fall into the “Maybe” or Sub-ML category. Feature stores are meant to curate and manage the data lifecycle and serve complex data sets. Enrich feature store streamlines the handcrafting of production-grade features for each use case. Data teams can collaborate on and reuse these features from a central feature marketplace.
With its extensible, modular design, Enrich allows the building of lightweight data apps that fit into users’ workflows and give them access to the latest continuously computed features they need.
Venkata adds, “With the tight timelines required for Sub-ML use cases, we needed to go more and more full-stack, bringing the data closer and closer to the end-use case. There were other elements like audibility, and reproducibility which were not just a requirements but mandates from a compliance point of view. Tacit knowledge management was also a point of concern, which we had to account for. All these were the design considerations when we were building the Enrich feature store.”
The Future Direction of Feature Stores
Scribble Data Enrich has two components, a feature store and an app store.
At the core of the feature store are transforms that look like modules that take data frames from one state to generate more data frames. The transforms in the Enrich feature store have the ability to note all the critical decisions, which get pushed to the end-users who are managing these pipelines. This allows them to make sure that they’re seeing the most important things that are happening to a data pipeline.
The second component, the app store started off with a handful of apps but currently stands at over 25 apps available out of the box for a wide variety of use cases. The idea behind these apps is providing a low code interface to build apps from available datasets. These could be light versions of a search interface, or a metrics app. Over a period of time, we have developed an app framework that supports the kind of workflows that users need in order to act on the feature engineering and data modeling. When we look at these apps, they can be broadly categorized based on three types of capabilities that are required.
-
Build an effective pipeline
-
Understand the context of datasets and features; and
-
Consume data assets and features across teams
All of these have been built to chip away at the friction points that we noticed across the data lifecycle.
Over the following months, Scribble data plans to spend a lot of time on the App Store, teaming it up with more widgets and making it more and more low code. “We’re also looking at more out-of-the-box integration with a bunch of different apps to accommodate more complex deployments,” concludes Venkata.
There are a lot more exciting details shared in Venkata’s talk where he shared more details on the design of feature stores for Sub-ML use cases, the size and scope of problems that Sub-ML can help address, their platform architecture, and more. Click here to watch the complete recording of the meetup.
To know more about how a shift in focus to a Feature Store for Sub-ML can benefit your business, schedule a call with our experts by writing to us at hello@scribbledata.io.
Do check out Carver Agents’ RegWatch – our new AI solution for real-time contextual regulatory risk intelligence, built for risk and strategy executives. Think of it as agentized mid-market LexisNexis. Visit https://carveragents.ai/.