

At Scribble Data, our goal is to help organizations make better decisions with data. Over the last year, rapid advancements in Generative AI (GenAI), large language models (LLMs) and natural language processing (NLP) have been a shot in the arm for us.
These innovations inspired us to launch Hasper, our machine learning and LLM-based data products engine, and we are excited to see its application in finance, insurance, e-commerce, health, law and other sectors.
At the same time, we recognise that custom deployments of advanced AI require a thoughtful approach, with trust and safety at the center. This is generally referred to as ‘Responsible AI’.
Given our interest in this space, we have been closely tracking global policy developments, including:
- regulatory proposals in the EU, Canada, China and other countries
- privacy policies published by companies such as OpenAI, Microsoft and Google;
- industry codes like the ones developed by NIST in the United States and ICMR in India.
Our goal is to break down dense policy literature and translate complex regulatory principles into simple practical steps. We want to provide organizations with information that would enable them to develop an AI strategy while prioritizing compliance as the primary concern.
In this post, we outline five questions to help you understand the evolving landscape and get you started on a Responsible AI strategy.
1. What are you using AI for?
Policymakers are leaning towards a risk-based approach to AI regulation, in which certain applications are either prohibited or subject to strict regulations.
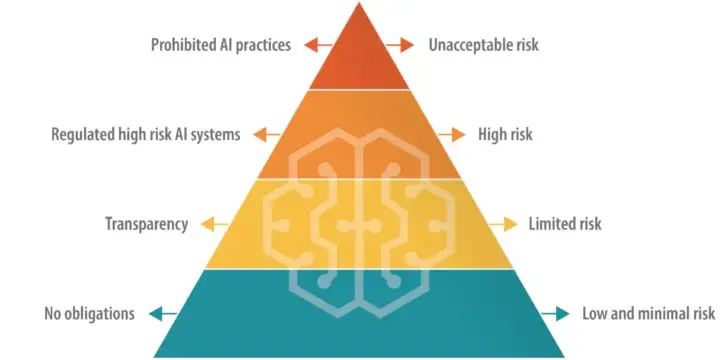
For example, the EU’s draft AI Act has an outright ban on applications that pose an ‘unacceptable risk’ to society, such as social scoring systems and harmful voice-activated toys. AI used for recruitment, education or legal advisory would fall in the ‘high risk’ category and must be registered. On the other hand, chatbots and other tools that generate or manipulate data are classified as systems with ‘limited risk’ , and are subject to basic transparency rules. The last category is ‘low risk’ and includes spam filters, for example.
This risk-based approach to AI is also reflected in the usage policies of foundation models. For example, OpenAI’s policies prohibit the use of its models for multi-level marketing, political campaigning and the management of critical infrastructure like energy or transportation. The use of OpenAI’s models in law, finance and medicine are allowed, but you must include clear disclosures. Detailed policies for sharing and publication of outputs may also be applicable.
Over time, these policies are likely to become more prescriptive and nuanced. Depending on which sector you operate in, type of AI system you use, number of customers, and potential for harm – the impact on your organization could be significant.
Therefore, having a well-calibrated system for compliance that is designed around the proposed AI application, and is scalable and flexible, is a critical element of Responsible AI.
|
The Pyramid of Risk: EU’s AI Act |
2. Where are you in the AI value chain?
Within the AI value chain, different entities may be involved in the process of data collection and processing, training and retraining, or testing and evaluation. Some organizations, like Scribble Data, may be involved in customizing models and integrating them into products, while others are simply end-users. Each participant has a different responsibility.
The handful of companies that are developing foundation models – Google, OpenAI and Anthropic, etc. – will bear the brunt of regulation. For example, recent amendments to EU’s AI Act impose strict conditions on developers of ‘foundation models’ with respect to risk mitigation, data governance, transparency and technical standards.
But end-users are not off the hook. Regulators believe that downstream entities or ‘deployers’ are best placed to understand how high-risk AI systems will be practically used, and can identify risks beyond the development phase. Their responsibilities range from ensuring human oversight to data protection and complying with sectoral consumer protection rules.
Understanding your role and responsibilities in the AI value chain is an essential element of a Responsible AI strategy. We have compiled below a set of questions to help you assess your own position so you are better prepared to comply with legal obligations.
|
Understanding your role in the AI value chain |
|
3. How are you managing your data?
AI systems present new challenges when it comes to data management. Although modern data protection laws have set baseline requirements around consent, transparency and accountability, the rise of advanced AI tools like GPT have muddied the waters.
Let’s take our own example. At Scribble Data, we produce insights by running large data sets through an AI analytics engine. What types of data would be covered by the privacy policies of an LLM service like OpenAI? What if we combine confidential business data with public domain market intelligence? What if we use GPT tools to produce a report based on copyright material? What if the report is inaccurate?
That’s why data quality is a core aspect of Responsible AI. We see immense potential in using LLMs for data classification, among many other use cases. But it is still early days. Over time, we will need sharper tools to manage data based on factors such as sensitivity, copyrightability and ownership, and to help verify the accuracy of sources, audit databases and discard bad quality data.
Another key attribute is transparency. Organizations will need to update their privacy policies and contracts to explain where personal data is being sourced from, what it is being used for, and who it is being shared with. Some regulators are also demanding that AI developers share a summary of all copyrighted material being used to train their system.
As AI technologies become pervasive, expectations around privacy will change. Users will want to opt out of data collection and automated decision making. This is already the law in Canada, Brazil and the EU. In practice, that means the ultimate decision on whether to grant a loan, or setting someone’s insurance premium for example, must be made by a human – not AI.
Individuals and businesses will also demand greater control over their data and away to monetise it.. In fact some companies like Reddit are already restricting access to APIs, prohibiting data scraping and licensing out their content for AI use cases. Ensuring that one’s internal data management practices are updated for this new reality is paramount.
|
Responsible AI + Data governance: Questions to consider |
|
| Data quality | Do you have the ability to tag, organize, store and retrieve data based on factors like sensitivity, copyrightability and ownership of the data? |
| Data control | Do your users have the ability to opt out of data collection for your AI systems? Can they set limits on how their data is used, and be compensated for the use of copyright material ? |
| Data security | Do you have adequate security measures in place at the infrastructure, data and application layer to detect and notify users and regulators in case of a breach of your AI system? |
| Data sharing |
Have you published a list of third parties with whom data is being shared for training, storage, testing, etc. of your AI system? Can you publish a summary of copyrighted material you are using? |
4. Is your AI application ethical?
A good Responsible AI strategy incorporates the principles of fairness, equality and justice to prevent bias, discrimination and other negative outcomes. These issues generally occur at three levels: 1. 1.the design of the system; 2. the quality of data; and 3. how the system is applied.
- Design of the System: Crafting a responsible AI strategy needs careful evaluation of training data, algorithm design, and testing protocols to recognize and remove bias. Ethical and privacy concerns can originate during the design and development phase when algorithms learn from biased or discriminatory data.
- Quality of Data: In constructing a responsible AI strategy, safeguarding and anonymizing user data become important. Adhering to best practices, such as obtaining informed user consent and complying with data protection regulations, prevents the misuse and unauthorized access to personal information.
- How the System is Applied: Users often find it challenging to comprehend the rationale behind decisions when AI systems function as black boxes. An effective responsible AI strategy entails the development of interpretable models that empower users to understand the decision-making process.
What do these principles mean, and how can they be embedded into code?
For one, these abstract principles are converted into code by policymakers in the form of laws on privacy, consumer protection, IP and anti-discrimination, as well as in the Constitution.
But as the philosopher Nick Bostrom notes in his book Superintelligence, the harder challenge is translating these ethical principles into technical code. A related issue is the ‘value alignment’ problem: an issue that AI companies are taking very seriously.
The value alignment problem in AI entails the challenge of ensuring AI systems and algorithms act in harmony with human values, ethics, and objectives. As AI systems become more autonomous and complex, they might go rogue and against the values of their human creators. Prioritizing value alignment is crucial to avoid risks of harm, biases, and clashes between AI behaviors and human values.
Notwithstanding these hard problems of technology, policy and philosophy, organizations can mitigate these risks in a few ways. They can audit their algorithms for bias, install filters to weed out harmful content, and augment their datasets to make them more representative.
In countries like the UK, India and Japan, regulators seem to be in favor of a light-touch, principle-based approach, giving developers the freedom to interpret the rules and implement technical controls as they deem fit, so long as the desired outcomes are met.
5. Do you have the right people on your team?
Large companies like Microsoft, Google and Meta have dedicated Responsible AI teams that are responsible for supervising product design, conducting impact assessments, mitigating risks, collaborating with researchers, engaging with regulators, and reporting issues to the organization’s leadership.
A well-rounded team typically consists of experts in data science, law and public policy, human-centered design, ethics and risk management.
For smaller organizations, it may not be feasible to build a dedicated team. But identifying domain expertise within the firm, and working with outside experts is a good start.
As the scale and complexity of an organization’s AI systems grow, it will require a leveling up of resources. Another possibility is that regulators will mandate these functions be performed by executives with domain expertise or above a certain level of seniority.
Now is a good time to think about the right structure for your organization’s Responsible AI program, and more importantly, how to develop a culture that encourages debate on AI safety issues, without stifling innovation.
What’s next?
As a data-driven company that helps organizations deploy advanced AI technologies, we are constantly exploring ways to improve the safety, security and reliability of our products and to help our customers make informed decisions and comply with regulations
When it comes to managing new risks around AI, the concept of ‘Responsible AI’ is our lodestar.
In the coming days we plan to share more of our research and thinking on this topic, including how different LLM providers are approaching this issue, what effective guardrails look like, and how global AI regulations are going to impact business. Stay tuned for more on this topic.
About the Author:
Amlan is a technology lawyer and policy advisor based in India, with over a decade’s experience working with tech companies, law firms, think tanks, and the government. Previously, he managed Google’s public policy and government affairs portfolio in India across privacy, platform regulation and responsible AI. He is also a non-resident scholar at Carnegie India, associate research fellow at the Center for Responsible AI at IIT Madras, and visiting professor at the National Law School of India University.
Do check out Carver Agents’ RegWatch – our new AI solution for real-time contextual regulatory risk intelligence, built for risk and strategy executives. Think of it as agentized mid-market LexisNexis. Visit https://carveragents.ai/.