

We live in a hyper-digital world, and due to the nearly infinite number of data sources that surround us, the volume of data generated collectively by individuals, applications and corporations is larger than ever. With such a monumental amount of data to sift through, two core principles have become increasingly important:
- Metadata – Make it possible to identify, categorize and search large data sources efficiently
- Data Sharing – Make it possible to share information between different stakeholders
In this article, we will answer the question “what is metadata?”, understand the principles of data sharing, and explore how these two are related.
What this article is about
This article talks about symbiotic, mutually beneficial agreements between businesses for buying and selling each other’s data.
Consider the case of email providers having to fight spammers and scammers. Being able to securely share data regarding account activity of suspected malicious accounts helps reduce the incidence of abuse overall.
As another example, imagine an e-commerce business and a construction company sharing data. For the e-commerce business, discovering untapped high-income localities in the area could help them ramp up delivery logistics for that area. Likewise for the real estate developer, learning about geographically adjacent pockets of high-spend users can help plan future, fancier construction projects.
The key here is that all participating organizations derive genuine value from discovering trusted external data sources to grow their business.
What this article is NOT about
We will not touch on how your behaviour on one app changes your experience on a related one under the hood (You add contacts to one app, and they magically appear as ‘suggested friends’ on another). While exploring the intra-company nexus is valuable, it is not the focus of this article.
What this article is DEFINITELY NOT about
This article is categorically not about the infamous rampant “data brokerage” industry where entities exist solely to unethically acquire customer information and sell it to anyone willing to pay a price. Lax regulation and glaring loopholes have allowed the industry to run rampant with unethical behaviour with complete disregard for the privacy and well-being of the end consumer.
We want to shed light on legitimate organizations adding economic value by sharing data in an ethical, regulated manner.
What is Metadata?
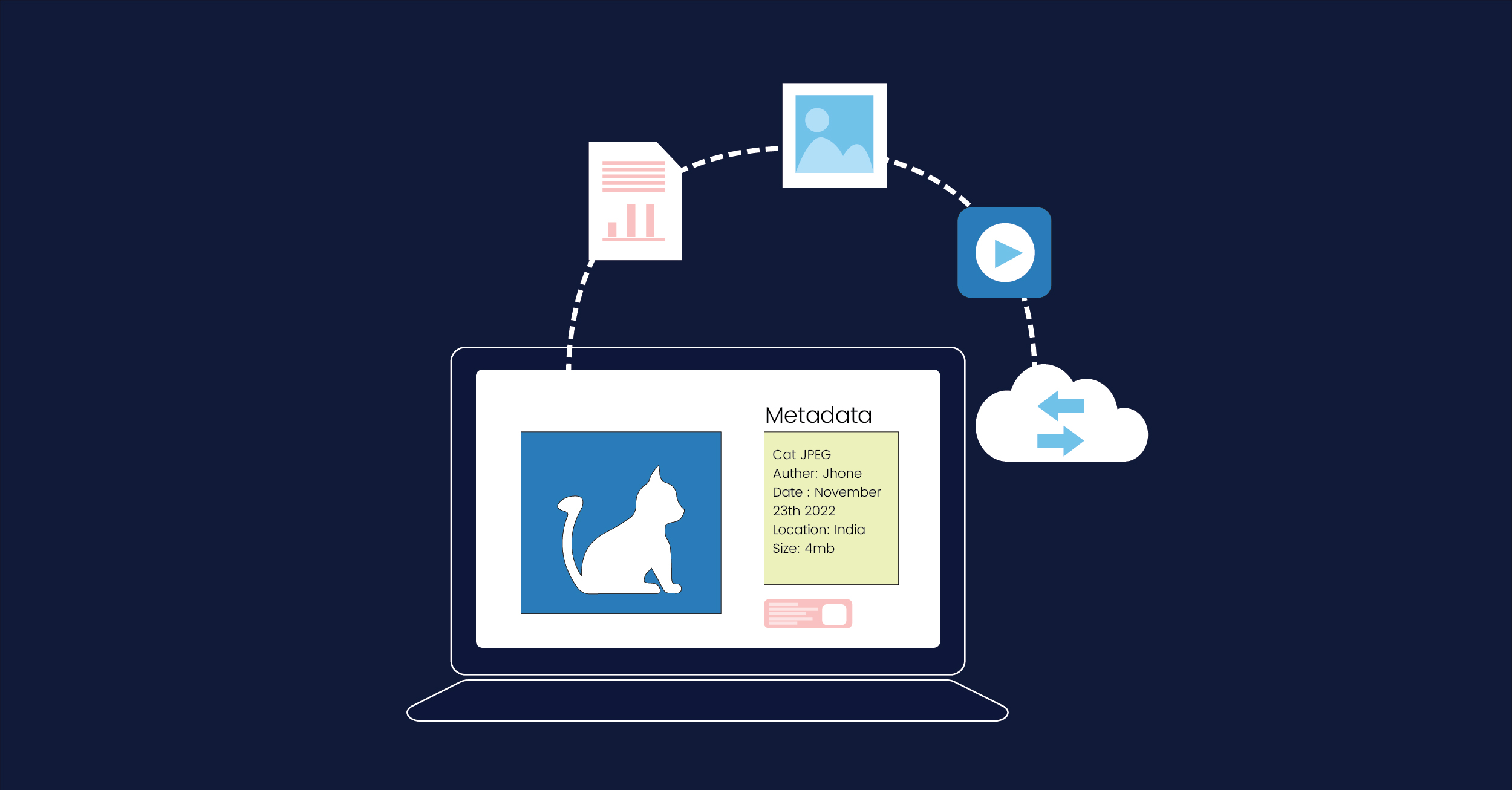
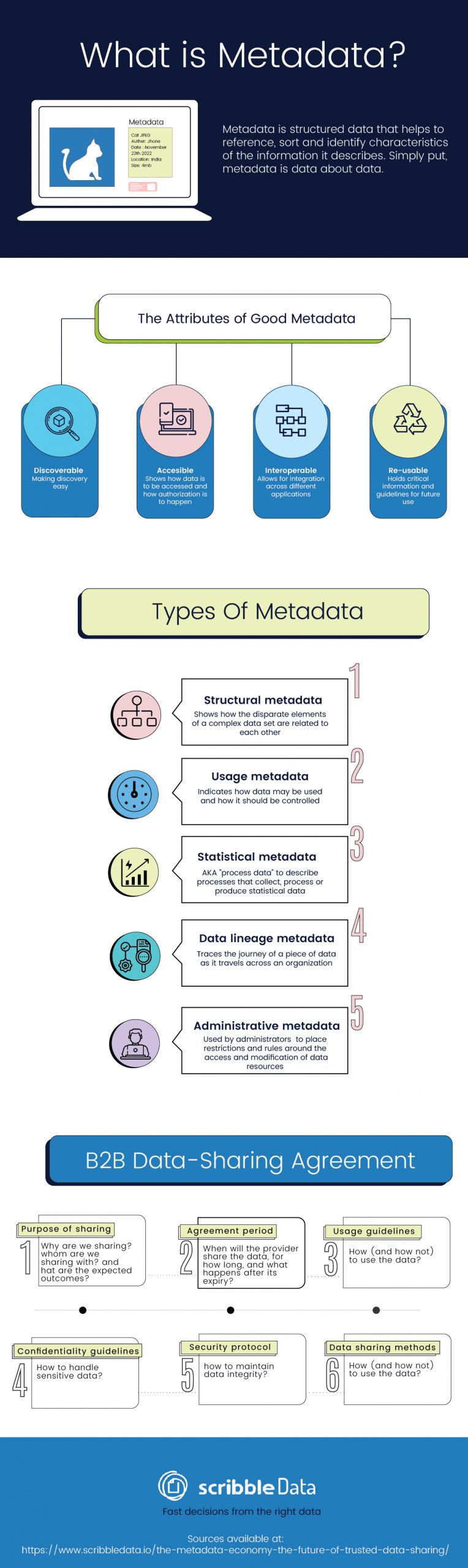
Metadata is structured data that helps to reference, sort and identify characteristics of the information it describes. Simply put, metadata is data about data.
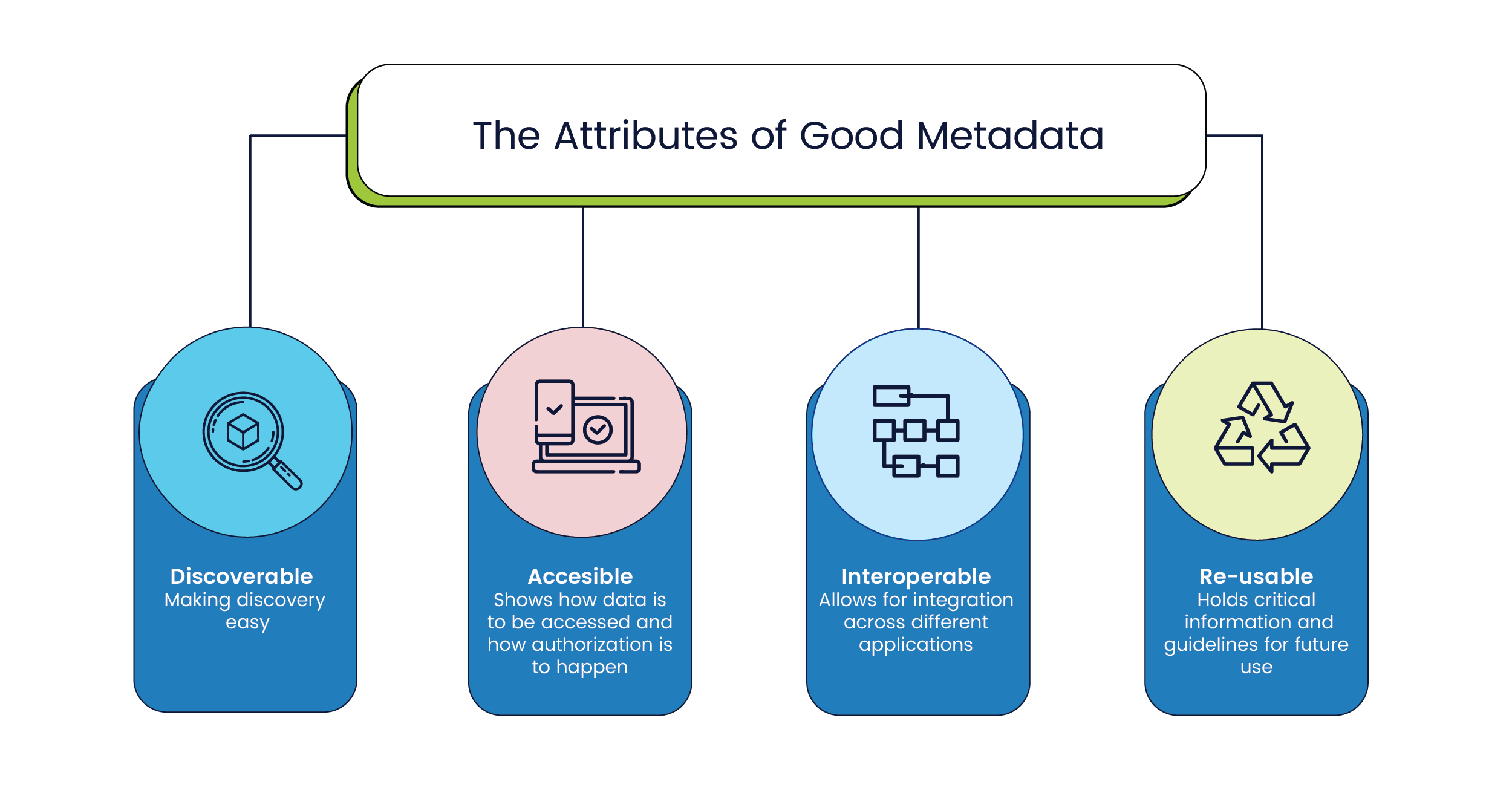
Good metadata ensures that data has the following attributes:
- Discoverable: Metadata makes it so that you can easily discover relevant data. Especially for non-textual file formats such as pictures, audio or video, metadata provides important context since most searches are done using text inputs. And with recent advances in feature engineering using neural networks, vector representations are increasingly being used as metadata to describe non-textual data sources.
- Accessible: Metadata specifies how data is to be accessed and, occasionally, even points to how the authentication and authorization of said data must happen.
- Interoperable: Metadata allows the integration of different data sets and allows data to be used with different applications for storage, processing, and analysis.
- Re-usable: Metadata holds crucial information about the structure of a data set including definitions, information about how data was collected and even guidelines for how it should be read.
The language of metadata is written in such a manner that both humans and computer systems can understand it . Businesses in various fields such as engineering, financial services, healthcare, and manufacturing extensively use metadata to improve the quality of their products and services.
Another common application of metadata is to enable search engines on the Internet. Meta tags are used to describe a page’s contents and keywords related to the topics that a particular page covers. Google and other search engines use this metadata as an important part of the overall score that determines the relevance of a particular page to a search query.
Types of Metadata
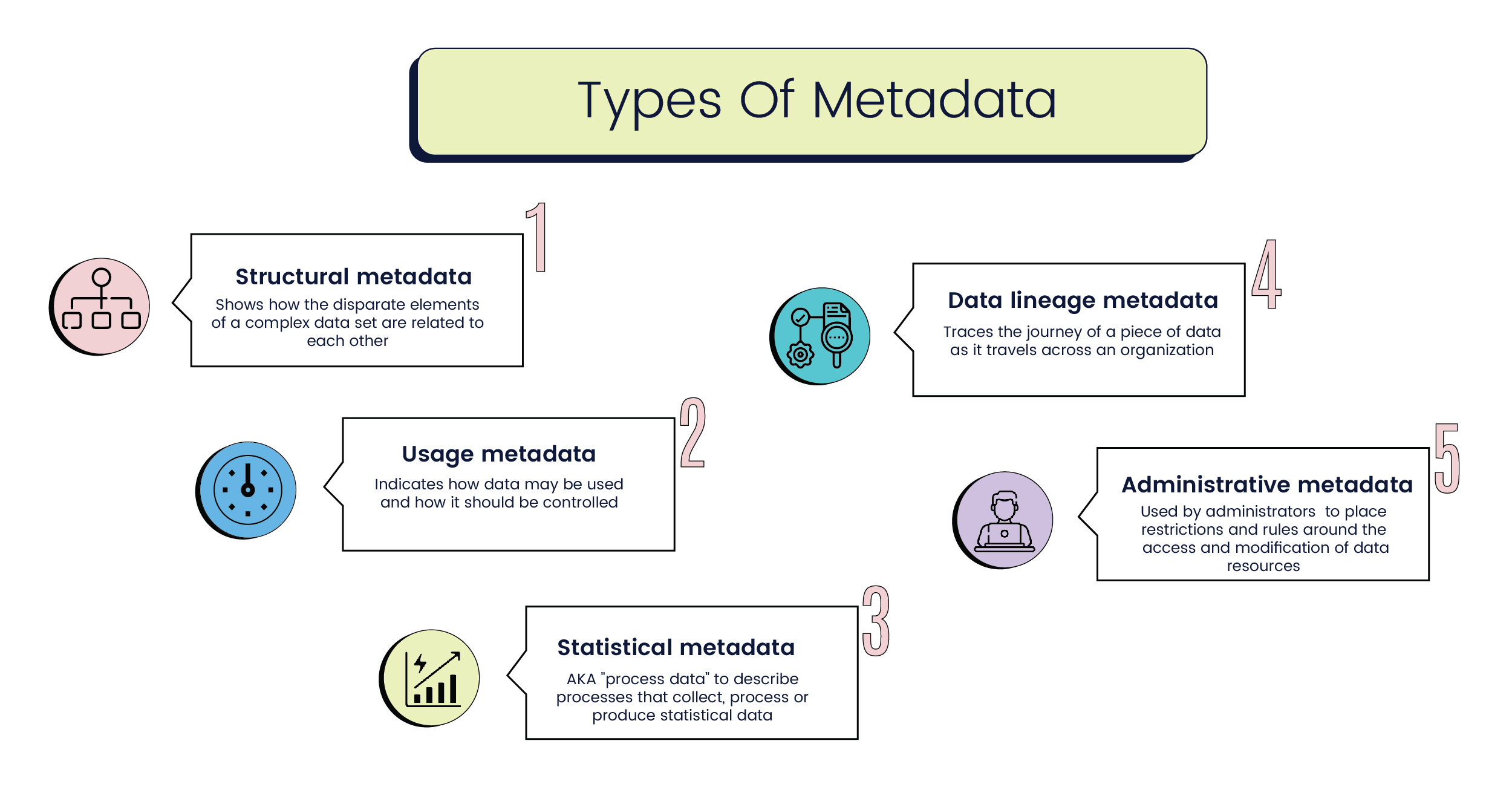
Metadata is classified based on the functions it performs in a particular implementation of information management. Some commonly used types of metadata are as follows:
- Structural metadata: Used to indicate how disparate elements of a complex data set are related to each other. For example, an audio platform might use structural metadata to organize individual ‘pages’ of audio into one chapter, and subsequently collate multiple chapters into one ‘volume.’
- Usage metadata: Indicates how data may be used and how it should be controlled. This is modified every time a user accesses the base application. Businesses can identify market and behavioural trends based on the usage metadata to modify their services and messaging in real time.
- Statistical metadata: Also called process data, statistical metadata may describe processes that collect, process, or produce statistical data.Used to organize surveys, compendiums, and archives of reports such that they may be properly read and interpreted.
- Data lineage metadata: Traces the journey of a piece of data as it travels across an organization. Original documents that need to maintain their structural integrity are often paired with lineage metadata to avoid any errors in data quality. Especially in government applications, tracing the lineage of a piece of information is customary practice.
- Administrative metadata: Used by administrators to place restrictions and rules around the access and modification of data resources. Administrative metadata is an important part of research work and includes details such as the creation date , size, and archiving requirements for different data units.
What is Data Sharing?
The enterprises of today use a complex web of interconnected systems for every business process imaginable. Whether for dissemination of vast volumes of data across a gigantic global organization or to make data-driven decisions in-house, data sharing has become increasingly important.
To put it simply, data sharing refers to sharing a set of data with multiple users, companies, or applications without compromising data integrity for all entities consuming it.
Data sharing between organizations has been around since before the advent of the internet. However, recent developments in technology and the adaptation of legislative frameworks to digital spaces have made it possible to accelerate the scale of data being shared dramatically.
What are the components of a B2B data-sharing agreement?
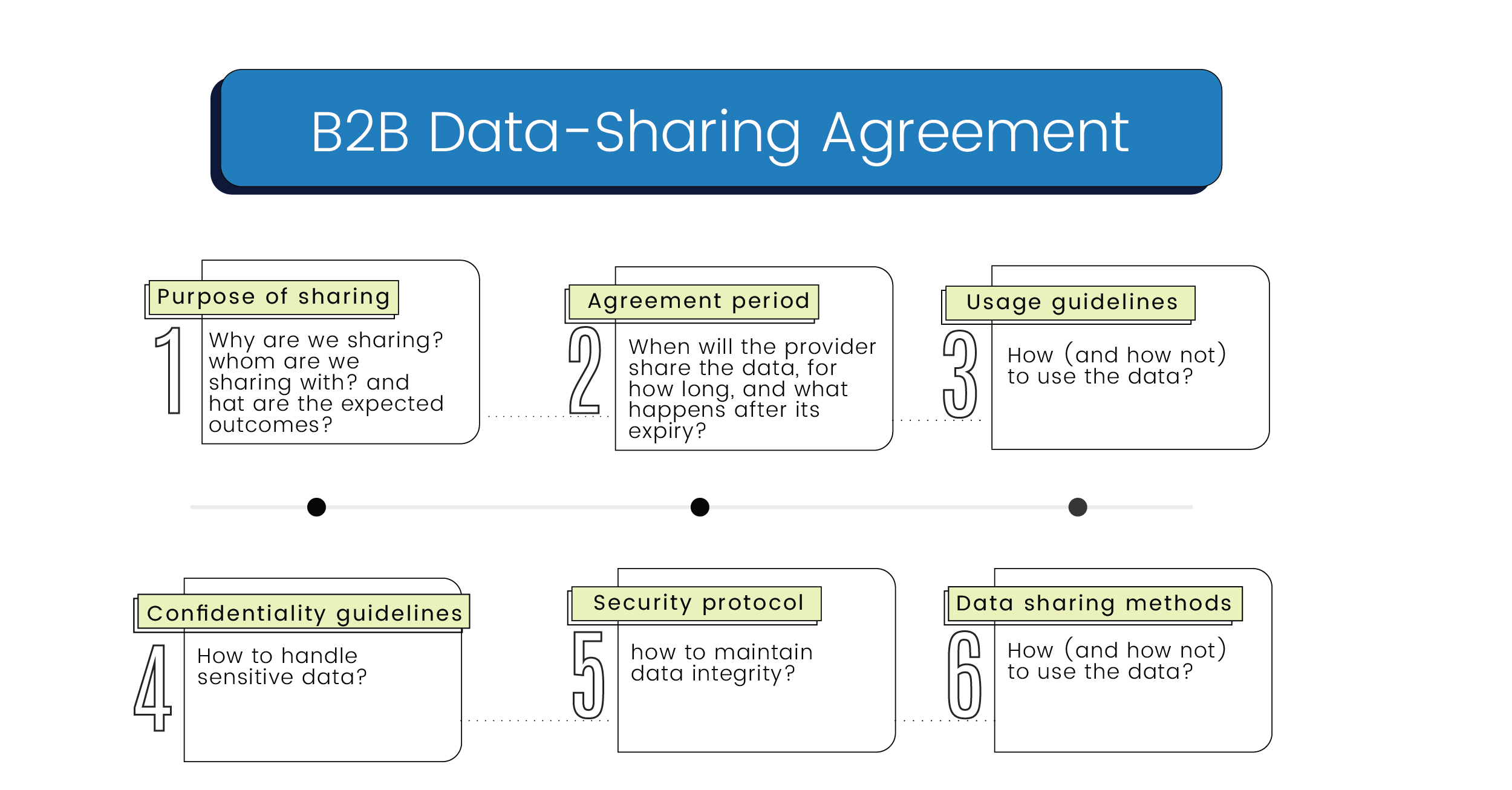
A typical data-sharing agreement will include the following items. This list is not exhaustive as special considerations may need to be made for a specific dataset or provider.
- Purpose of sharing: The agreement must clearly lay out why data is being shared, who it is being shared with, and what the expected outcomes are from this exchange of information.
- Agreement period: The agreement must clearly state when the provider will share data with the recipients, and how long the recipients of the data will maintain access to the data. It is also important to mention what will happen to the data once the agreement period expires (return to sender, deletion from recipient storage etc).
- Usage guidelines: The agreement should state, in as much detail as possible, how the recipient of the data is supposed to use it. This will include any intended restrictions on how the data or findings can be used. Recipients may also be required to document how they use the source data. Guidelines should include language about whether the recipient can share or sell any part of the information or reports they have access to because of the source data.
- Confidentiality guidelines: The agreement must state how the confidentiality of the data is to be maintained. Sensitive datasets may require multiple levels of security clearance to protect the privacy of information like salaries or medical information.
- Security protocol: The agreement must state how the data integrity should be maintained. This will include policies around backup and storage of said data, and other information such as passwords and even restrictions around physical access to server locations if necessary.
- Data sharing methods: The agreement must outline the procedures and safeguards to be followed while transferring data from point A to point B. It will include information about the physical and electronic transfer of data – which applications are to be used, how to guarantee a secure connection while transferring and how the data will be encrypted before transferring it.
How Data Sharing Between Companies Happens in the Real World
To drive home our understanding about data sharing and metadata, let us imagine a situation in which Company A and Company B have entered into a mutually beneficial data-sharing agreement.
Depending on what kind of data is being exchanged between A and B, it could be hypothesized that consumers of either A or B have the most to lose if something goes wrong. Because although customers may have consented to A or B storing and using their data, they have not necessarily agreed to allow the companies to share their data with each other.
To make sure all of the stakeholders in this data-sharing agreement are protected, the following framework can be used involving two key players
- A Trusted Data Custodian (TDC)
- Metadata
The TDC will be a for-profit organization that establishes trust with companies, enables valuable discoveries of data and opportunities for each company and then sets up a framework through which data transactions can happen.
Once this is in place, data sharing between companies can happen in the following three phases.
- Repository
In the first phase, the TDC operates like a confidante for multiple businesses that trust it with their data. The TDC will independently audit and rate the quality of data held by each company that collaborates with them.
These companies will then confide to the TDC about business use cases or intended goals for which they need external data. - Discovery
In the second phase, the TDC plays matchmaker, suggesting beneficial dataset matches to companies based on how useful their data sets will be to each other based on their business needs.
Metadata plays a crucial role in this part because it describes individual company datasets’ technical, structural, and contextual contents. Detailed metadata aids the TDC in accurately predicting which companies can benefit the most from sharing data with each other. - Facilitation
Once both sides of the data-sharing agreement (source and recipient) have agreed to the transaction, the TDC springs into action. It performs several functions at this stage, including: -
- Establishing the period, purpose, and boundaries on the usage of data
- Establishing strict, unimpeachable standards for data transactions that comply with governmental policies and specifically addressing the privacy of any parties that are identified by the data
- Maintaining a ledger that logs the quality and quantity of information exchanged, especially if the data sharing is a multipartite arrangement
- Setting up a robust, secure, and transparent data transfer process that can be audited by any of the participants or a third party. Competitive advantages for the TDC will emerge from the technology they use to facilitate the process.
- Measuring the impact of the data sharing
- Growing the cycle of trust between companies sharing data
A Short Note on Metadata
To date, the potential of metadata remains underutilized because most companies are caught in a cycle of focusing on collection and storage. Additionally, many businesses are leaving money on the table because they simply do not have the right people, processes, or tools to utilize the data they already have properly.
It is possible to annotate several attributes about data that can make the pre-processing of data rich and insightful. Adopting the right tools and processes for metadata management in conjunction with emerging technologies with AI and ML can dramatically improve the ad-hoc analytic process. Users can get a much clearer preview of what to expect in the actual data, which will make sharing, querying and analyzing data much easier for internal company use and sharing data with other companies.
Stay tuned to the Scribble Data blog to learn more about metadata, data sharing and the science of information.
TL;DR Version
Do check out Carver Agents’ RegWatch – our new AI solution for real-time contextual regulatory risk intelligence, built for risk and strategy executives. Think of it as agentized mid-market LexisNexis. Visit https://carveragents.ai/.