


We speak to a number of organizations who are in the process of building and deploying data infrastructure and analytical processes. Organizations face a number of challenges that prevent them from meeting their analytical business objectives. The idea of this note is to share our thoughts on one specific challenge – high cost. Specifically:
- Cost model – Deconstruction of cost of data infrastructure
- Drivers – Drivers of each cost dimension
- Recommendations – Actions to address each driver
Simple Cost Scaling Model for Data Infrastructure
From our experience, when we abstract out the cost structure, it looks like the equation below. For each usecase that a business is considering, there is a transaction or threshold cost due to existing infrastructure and process, and a usecase-dependent, effective cost of delivering on the usecase.
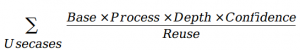
The various dimensions of the cost model are:
- Base: Threshold transaction cost that has to be paid always due to the way the systems are organized
- Process: Task-specific additional coordination cost
- Depth: Cost scaling based on the complexity of the modeling and delivering
- Confidence: Cost scaling due to degree of trust needed in the output
- Reuse: Cost amortization from the ability to reuse assets, process, and outputs
Drivers of Cost Dimensions
We expand on the underlying drivers for each of the cost dimensions:
- Usecase Selection: A usecase for which there is limited buy-in and unclear business benefit results in loss of interest over time. Projects are sometimes shutdown midway resulting in loss of time, and waste of effort.
- Base Complexity: The complexity of the IT systems increase the transaction cost for every data project at every step. The process of discovering what data exists in the system, how to access it, whether it is relevant and usable could be time consuming. Further, implementing the data project may require workarounds and additional modules.
- Process: Each usecase may involve different degree of coordination between people and organizations, and integration between systems. Friction in this activity due to economic or other issues increases the overhead for a given data project.
- Depth: Questions in the organizations can be framed and addressed at varying levels of scale, accuracy, and relevance. The cost increases with scale (e.g., every customer instead of a cohort), accuracy (e.g., fundamental drivers instead of proximate causes), and relevance (e.g., integrated into the workflow at the exact time and detail instead of loosely enabling a decision).
- Confidence: Analytical process tends to be error prone. Testing the answer for robustness over dimensions such as time, space, and user groups often is several times the cost of initial analysis. This is often due to the fact that systems are often not designed for controlled experimentation. In addition, more infrastructure has to be built to repeat the experiments.
- Reuse: Questions in an organization tend to build upon previous questions, and systems are required to create the ability to reuse the process, technology, and data assets created. Mechanisms for managing the artifacts created, and sharing the results are often missing in enterprises. Analysis attempts often start from scratch.
Common across all these drivers is the people cost. As the cost of the technology is dropping over time, the cost is shifting to people, and this cost is growing rapidly with time.
Recommendations
The cost model immediately shows how the cost can be reduced over time:
- Find Good Quality Use cases: It is worth spending time to find a good quality usecase to drive the development. Such usecases have clear and positive economics that aligns people (motive), meets data and people preconditions (means), and commitment from the organization with resources (opportunity).
- Incentivize IT for Data Consumption: Data engineering can account for upto 80% of the data project. Architecting systemsand data infrastructure for data discovery and consumption will reduce the transaction cost for all projects. It is not simple though. IT organizations are overburdened, and incentivized for functionality and robustness. They are not incentivized to make technology and other choices that enables the organization’s data journey. There is often technical debt that already built up over time that needs to be addressed first.
- Build Well-Oiled Team: Most data projects involves coordination across business functions including IT, business, and data teams for a number of reasons including formulation of the problem, selection of methods, and uncovering tacit knowledge. Ensure low friction and high degree of collaboration.
- Build Balanced Team: Data projects have three main areas – modeling/statistics (20-40%), engineering (40-80%), and domain (10-30%). Strong and proportionate representation from each of these areas will enable a defensible result, an efficient implementation, and a business-relevant output.
- Sharing Culture: Data analysis generates significant amount of knowledge about an organization’s business including customers, product, and data assets. Providing a mechanism to share work products, and incentivizing the same will save significant amount of resources for the organization by reducing errors and reusing the work done.
Takeaway
The high cost of data infrastructure and projects can be understood and reduced. But discipline in the thinking and execution is required to achieve the same. Data science is more than anything is a test of the character of the organization.
Dr. Venkata Pingali is Co-Founder and CEO of Scribble Data, a data engineering company. Their flagship product, Enrich, is a robust data enrichment platform.