

Big data is an indispensable part of our modern existence, powering several real-world applications such as personalized marketing, healthcare diagnostics, fraud prevention and many more that have transformed the way we live, work, and communicate with each other.
However, since big data has become such a critical component of organizational decision-making, it is imperative to ensure that the data being used to make these decisions is accurate. Faulty conclusions drawn from big data can have major consequences, such as wasted resources, missed opportunities, and reputational harm. According to a report by Gartner, poor data quality costs organizations an average $12.9 million. The report also highlighted that poor data quality increases the complexity of data ecosystems and leads to poor decision-making.
In this article, we will analyze the impact of bad data and try to chart a path to allow us to leverage big data while avoiding potential drawbacks.
Big Data Is A Double-Edged Sword
| To illustrate just how disastrous decision-making based on faulty big data can turn out, consider the example of PredPol, a predictive policing algorithm used by the state of California in the USA.
PredPol is a machine learning algorithm developed by a team of criminologists, mathematicians, and social scientists that uses historical crime records along with some other variables to predict where future crimes might occur. However, what sounded like a good idea on paper turned out terribly because the algorithm was found to be biased against people of color. Researchers from the Human Rights Data Analysis group discovered that PredPol was more likely to recommend police patrols in neighborhoods with populations of color, leading to a disproportionate amount of arrests and police stops in those areas. Additionally, the study discovered that PredPol had no statistical impact on crime rates and may have ended up making things worse in those communities, which prompted several police departments within California to stop using the algorithm. |
The Data Quality Problem
Now that we’ve talked about the consequences of faulty data, let’s discuss why data quality is such a persistent problem even after almost three decades of constant research and development in the field.
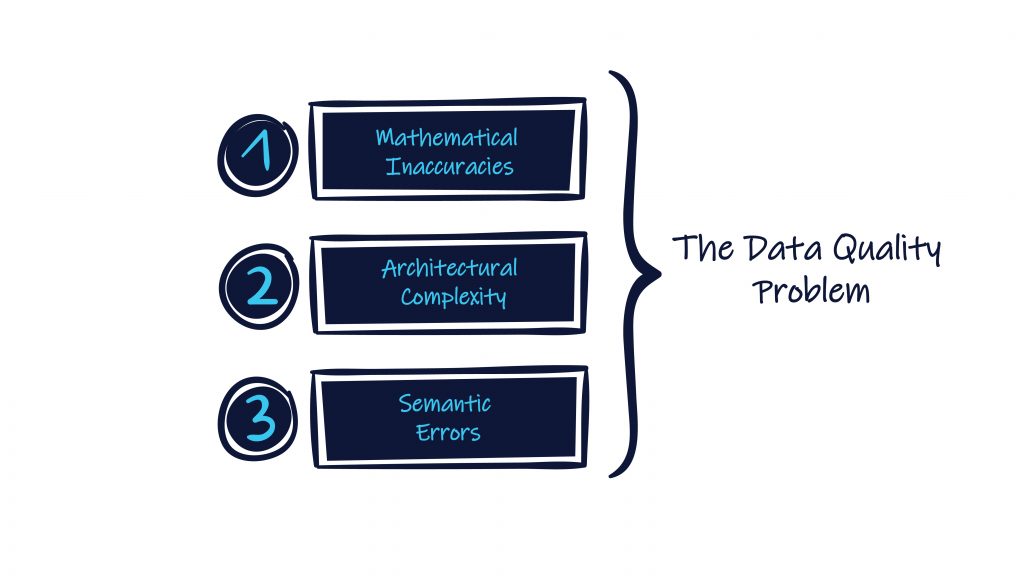
- Mathematical Inaccuracies
At the core of data quality is the issue of mathematical accuracy. Any inaccuracy in the data can result in incorrect decisions that propagate downstream. As data flows through various stages of processing, it is subject to a multitude of operations that can introduce errors – addition, deletion, multiplication, estimation, and more occur at every step of the process, from the application backend to ETL jobs and beyond. By the time data reaches the end user, it has gone through numerous transformations, and each of these transformations can potentially introduce errors.
- Architectural Complexity
The complexity of the problem is further compounded by the way data flows through an enterprise. Data transformations occur at the organization level, like a graph with nodes generating data and moving it to other nodes. The data gets copied and processed by multiple nodes, some of which use SQL, and others are applications performing specific tasks. The processed data is then stored in a database, further computations are performed, and then an application picks it up and performs additional computations before it is presented to the end user.
The primary reason that errors propagate through the system is that many of these nodes are opaque and undocumented. Their transformations are not well-documented, and it can be difficult to trace the path the data has taken.
- Semantic Errors
Simple data quality checks at the beginning and end of the process are not sufficient, as the errors are often semantic in nature. Semantic errors occur when the data is inconsistent or does not conform to the expected structure, meaning, or context.
For instance, an account balance may be represented by an integer or a float, but the syntax of the number is not the issue. The problem arises when the value of the bank account is wrong, which is a semantic issue, not a mathematical one. Similarly, if the data set contains incomplete, outdated, or missing data, such as missing values or null fields, it can also result in semantic errors.
These types of errors are challenging to detect with application-level checks because they are format-based in nature, and it is not always clear what impact a particular change will have on downstream processes.
Challenges With Observability
The combination of a DAG (Directed Acyclic Graph) like data flow at the enterprise level and the massive number of transformations that occur make it extremely difficult to detect where any error originated and what impact it has had. This is particularly true for semantic changes that occur deep within the system’s different nodes, making it nearly impossible to pinpoint the exact location of the error. Even worse, sometimes decisions are made based on erroneous data before the error is detected, leading to catastrophic consequences.
Traditionally, the proposed solution to this problem has been observability. The idea behind this approach is to monitor every single table, column, and other data source to detect any errors. However, this approach has its own set of challenges.
- The sheer number of tables and columns in an organizational data set makes it difficult to determine which ones need to be observed and how. Every table added needs to have a corresponding set of checks and balances, complicating things even further.
- What constitutes a reasonable value for any database column is not always obvious, and it is often determined by the semantics of the application. For example, only the banking application can tell if there is something wrong with an account because the numbers do not add up
- Most observability applications do not understand semantics related to data quality and other relevant factors. They primarily focus on metrics such as minimum and maximum values, which may catch obvious errors but fail to detect more subtle ones.
Furthermore, recent solutions such as observability systems are often expected to function as stand-alone processes. This approach assumes an organization has the resources to set aside people to build these systems and watch them. However, in most cases, this is not a viable solution. Most SME organizations simply do not have the resources to dedicate people to monitor observability systems continuously. Moreover, even with such systems in place, they may not cover all paths through which data flows through the entire organization.
How We Can Tackle Bad Data
Any data quality solution must be an end-to-end process that considers the impact of all intermediate nodes. Correctness is an end-to-end property, and you cannot improve data quality by addressing only a portion of the process. As a result, preventing bad data and ensuring data quality must become a top priority for organizations. It is a multi-pronged undertaking that involves strategies such as:
- Establishing robust data quality standards: The first step in preventing bad data is to establish clear data quality standards and guidelines for data collection, storage, processing, and analysis. This includes defining data quality metrics such as accuracy, completeness, timeliness, and consistency.
- Rigorous quality checks: Organizations can implement data quality checks at various stages of the data lifecycle to ensure that data meets the established quality standards. This includes automated data validation, error detection, and data remediation processes.
- Investing in data governance: Data governance is the process of managing the availability, usability, integrity, and security of data used in an organization. This includes establishing a data governance framework, setting up data policies and procedures, and appointing a data governance team or officer.
- Training your workforce on best practices for data management: Data quality should become part of everyone’s job at an organization. Conduct awareness workshops and training programs for employees to ensure that they are following the best practices for data collection, processing, analysis, compliance, and security.
- Use data profiling tools: Data profiling and transformation tools can be used to identify anomalies, missing values, and inconsistent information. Tools such as Enrich offer audit trails for all data products to enable historical analysis and future verification for easier isolation and quantification of data errors.
- Employ defensive coding practices: Defensive coding is a series of coding best practices that reduce the potential for errors, bugs, and vulnerabilities in software. By anticipating errors and pre-emptively building safeguards into the code, programmers can offset the prevalence of issues.
There are several aspects of defensive coding – input validation, error handling, code reviews, testing, and modularity.
In conclusion, it is important to reiterate that there is no silver bullet solution to bad data, and it requires a combination of efforts, including end-to-end design, coding practices, and data processing workflows. Data quality management is a crucial and ongoing challenge that businesses must face and address to ensure that their data is accurate, reliable, and fit for purpose.
To learn how you can eliminate bad data, and solve persistent business problems, learn more about Scribble’s Enrich Intelligence Engine.