


As the complexity of data and systems that hold data grows, the cost of analysis increases due to time and effort spent in figuring out the feasibility, appropriateness, access, and management of data. We believe that a number of new low-risk and valuable applications can be built through creative application of metadata that can help cope with growing complexity and reduce cost of analysis.
Our pure metadata-based cloud product, Scribble Assist, is the first of many applications that will be built by the larger community. Our experience with customers has convinced us of the value of the approach and that a lot more will come. We discuss how we see the landscape of metadata applications.
About Metadata
Metadata is data about data. For example, the metadata of a tabular dataset could be the names of its individual columns and the metadata of a database of transactions is its database schema. In this discussion, the metadata is primarily about the existence, structure of the data, and sometimes about semantics. The exact nature varies with organization and depends on a number of factors including availability of standards, accessibility, and sensitivity of the data.
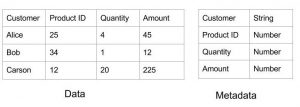
Metadata can have many other dimensions beyond the syntactic type of data. Some of them are shown below. Each of the dimensions helps with understanding the feasibility, value, and cost of the intended analysis.
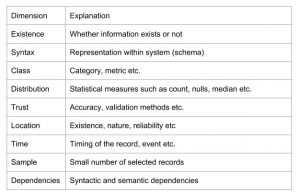
Reasons for Looking at Metadata
There are a number of reasons for looking at metadata:
- Lower Risk – Metadata has much less sensitivity associated with it than actual record. It does not add a lot of value to the person looking to compromise the system. The fact that Customer ID exists in a company is hardly new information even if it is leaked.
- Easier to Roll Out – Due to the fact that fewer approvals are required, it is possible to build metadata-based applications cloud-based, lightweight, and easily deployable within or outside the perimeter of the organization.
- Improved Efficiency – Simple metadata checks are enough to address a number of questions regarding feasibility, appropriateness, automated code generation, and cost of complex analytical tasks saving valuable resources for the organization.
- Cross-Organizational Visibility – Metadata can enable managed discovery of data across organizational boundaries without creating direct paths to data.
Applications that access data have to implicitly or explicitly address questions of security and privacy of data. Such applications have to be deployed behind firewall and require high degree of trust. These applications are therefore more costly to engineer and operate, and have longer debugging and upgrade cycles.
Metadata-only clearly limits the applications but can be seen as a facilitator of more complex and expensive analytical applications.
Applications of Metadata
Any aspect of the analytical application that relies on structure or minimal annotations of the data may be an application of metadata. They fall into three classes:
- Discovery – explore intended data application without accessing data
- Access – simplify and automate acquisition of data
- Transformation – simplify and automate transformations such as encryption
Discovery
Accessing and processing data is an expensive process involving obtaining permissions, programming systems, and managing data. Metadata can help with discovering a number of aspects of the planned application of data even across organizational boundaries at low cost:
- Feasibility – If there is no customer ID in transactions data, we simply cannot segment the customers based on purchase behavior
- New Opportunity – If there is information in datasets that allows us to link datasets or support unexpected dimensions of analysis, then they present an opportunity for new threads of investigation creating value for the organization
- Ambiguity – If there is ambiguity about classifying a record by some identifier such as store number, then additional work can be planned to address that ambiguity.
- Shape – Information on number of records, valid values, etc will help get the data exploration work started immediately without having to wait for access
- Trust – Knowing about integrity and history of a data dimension will allow us to determine whether or not to use that dimension.
- Coordination – Coordination costs involving data access can be reduced by knowing all data elements required for analysis, what past experience with the relevant dataset has been, etc.
Access
Discovery of the value and feasibility still does not eliminate the mechanistic process of access to data. Direct access to data may be difficult to obtain or not available for a number of reasons:
- Security – All access may be mediated by an entity enforcing policies and auditability.
- Efficiency – Systems with APIs and language interfaces such as SQL may require advanced skills. Intermediate entities can provide alternative simpler intuitive interfaces or mechanisms to increase increase trust and efficiency.
- Abstraction – The actual representation of the data may be different from that was shared. So an entity is required to translate the abstract to actual.
- Derived Data Only – The raw data may be too large and sensitive to ‘export’, and only processed output can be ‘exported’.
Scribble addresses (1) and (2). It provides a simpler interface to SQL and also provides auditability to all queries – all using metadata only. We anticipate that more such systems will be built over time for different kinds of data backends (SQL and NoSQL), use cases (data preparation, brokering etc.), user profiles, and delivery methods (GUI, scripted).
Transformation
Data goes through a number of transforms in its lifecycle such as integrity checks, encryption, sampling and creating datasets that depend on the structure of the data. Automated code generation for these have a number of advantages:
- Standardization – Use of organization-wide standard mechanism such as 7zip for encryption, coding standards, languages, and avoid divergence in tool chain.
- Auditability – Automatically generate audit trails for all transformations, and make it a default
- Efficiency – Low level syntactic details such as mysql interface commands can be hidden from the user.
- Additional Metadata – Additional metadata is generated that allows the organization to link other information such as person name or server used.
The code for these tasks can be readily generated, documented, and executed within a transformation framework. An example of this is dgit (opensource git for data) that provides.
Evolving Landscape
As the nature, distribution, and application of data evolves, we expect that new applications of the metadata will come to the fore. It should be seen as a yet another building block of the emerging organization data management platform.
Dr. Venkata Pingali is an academic turned entrepreneur, and co-founder of Scribble Data. Scribble aims to reduce friction in consuming data through automation.
Do check out Carver Agents’ RegWatch – our new AI solution for real-time contextual regulatory risk intelligence, built for risk and strategy executives. Think of it as agentized mid-market LexisNexis. Visit https://carveragents.ai/.