


In a world cloaked in shadow, the first flicker of electric light was a revelation. It sliced through the darkness, stark and bright. It changed everything. Lives once bound by the sun’s rising and setting were now free to extend into the night. Electricity was not just a discovery – it was a revolution.
Today, we stand at the brink of a similar precipice. This time, the revolution is not in the physical world but in the realm of information, knowledge, and language. It pulses within the circuits of neural networks. At its heart are Large Language Models – LLMs.
But this power, like electricity, must not be hoarded. Open-source LLMs stand as the guardians of this new frontier. They ensure this power flows not just to the few but to the many.
In open-source, we find not just innovation, but equity. It’s a call to arms, a rally for humanity’s collective genius. The promise of LLMs is vast. They could democratize education, breaking down barriers of language and access. They could revolutionize industries, from healthcare to law, making expert knowledge ubiquitous.
This is not a distant dream. It is a budding reality, growing each day as the open-source community nurtures these models.
What are the benefits of Open-Source LLMs?
In an age where giants like ChatGPT, Google Bard, and Anthropic Claude dominate the landscape of language models, the allure of open-source LLMs might not be immediately apparent. These closed-source titans, with their vast resources and cutting-edge technology, cast long shadows, setting benchmarks in AI’s capabilities and applications.
Yet, in this shadow lies a vast, untapped potential – the realm of open-source LLMs. These are not just alternatives, but necessary complements, essential for a landscape where innovation, accessibility, and diversity in AI are not privileges but common standards.
- Enhanced Data Security and Privacy: Open-source LLMs allow organizations to deploy models on their infrastructure, significantly enhancing data security and privacy, crucial for sensitive industries.
- Cost Savings: Eliminating licensing fees, open-source LLMs are a cost-effective solution for enterprises and startups, enabling the use of advanced AI technologies without a significant financial burden.
- Reduced Vendor Dependency: By using open-source LLMs, businesses can reduce their reliance on a single vendor, enhancing flexibility and preventing the risks associated with vendor lock-in.
- Code Transparency: The transparent nature of open-source LLMs allows for a thorough inspection and validation of the model’s functionality, fostering trust and compliance with industry standards.
- Language Model Customization: Open-source LLMs offer the flexibility to be tailored to specific industry needs, allowing organizations to fine-tune the models for their unique requirements, enhancing relevance and effectiveness.
- Active Community Support: The presence of a thriving community around open-source projects ensures quicker issue resolution, access to a wealth of resources, and a collaborative environment for problem-solving.

- Fosters Innovation: Open-source LLMs encourage innovation by enabling organizations to experiment and build upon existing models, particularly beneficial for startups looking to develop creative applications.
- Transparency in Development: Open-source LLMs provide a clear view into their development process, aiding in understanding the model’s decision-making process and ensuring alignment with ethical standards.
- Community-Driven Improvements: The diverse community contributing to open-source LLMs can lead to more innovative and robust solutions, enhancing the model’s capabilities through collaborative efforts.
- Avoidance of Proprietary Constraints: Free from proprietary constraints, open-source LLMs offer greater flexibility in use and integration into various systems, crucial for diverse application environments.
- Rapid Iteration and Experimentation: Open-source LLMs allow organizations to iterate and experiment more rapidly, enabling them to test changes and deploy updates without being constrained by a vendor’s release schedule.
- Access to Cutting-Edge Technology: Providing access to the latest advancements in AI, open-source LLMs enable organizations to stay competitive with state-of-the-art technology without the associated high costs.
- Ethical and Responsible AI: The open-source community’s focus on ethical considerations and responsible AI practices often leads to the development of more equitable and unbiased models.
- Educational Value: Serving as hands-on educational tools, open-source LLMs are invaluable for students and researchers to learn about AI and language modeling, promoting practical learning experiences.
- Interoperability: Designed for interoperability with a wide range of systems and technologies, open-source models facilitate seamless integration into complex IT environments, enhancing their utility.
With that in mind, let’s look at some of the most promising open-source LLMs out there in 2024.
GPT-NeoX
GPT-NeoX is an open-source LLM developed by EleutherAI. It is an autoregressive transformer decoder model with an architecture that largely follows GPT-3, but with a few notable deviations. The model has 20 billion parameters.
Key Features and Capabilities
GPT-NeoX is particularly powerful for few-shot reasoning, making the model more suitable for certain tasks like code generation.
The model can be used to build applications like text summarization, paraphrasing, code generation, content writing, text auto-correct, text auto-completion, and chatbots. It can also be used for unconditional and conditional text generation.
Deployment and Usage
Due to the model’s size, inference is most economical on a pair of RTX 3090 Tis or a single A6000 GPU, and fine-tuning requires significantly more compute. As per the GPT-NeoX models Github repository, at least 2 GPUs and more than 45GB of GPU RAM are needed, along with 30-40GB of system RAM.
GPT-NeoX is not intended for deployment as-is. It is not a product and cannot be used for human-facing interactions without supervision.
Limitations
GPT-NeoX-20B is English-language only, and thus cannot be used for translation or generating text in other languages. It also requires advanced hardware for deployment, which can challenge some users.
Community Perception
GPT-NeoX is seen as a potential rival to GPT-3, with some users noting that it is exceeding expectations. The open-source nature of GPT-NeoX is appreciated, as it allows for more flexibility and control compared to proprietary models like GPT-3.

LLaMA 2 LLM
LLaMA 2, developed by Meta AI, is the next generation of their open-source LLM. It is a collection of pre-trained and fine-tuned models ranging from 7 billion to 70 billion parameters.
The model was trained on 2 trillion tokens, doubling the context length of its predecessor, LLaMA 1, and improving the quality and accuracy of its output.
It outperforms other open-source language models on many external benchmarks, including reasoning, coding, proficiency, and knowledge tests.
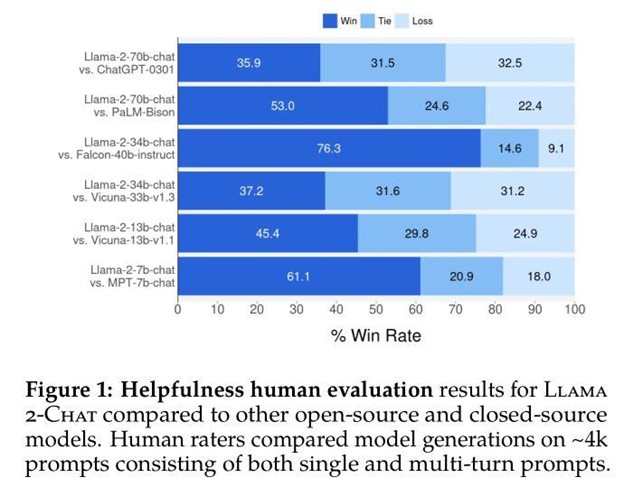
It includes models like Llama Chat, which leverages publicly available instruction datasets and over 1 million human annotations. It also has Code Llama, a code generation model trained on 500 billion tokens of code that supports common programming languages like Python, C++, Java, PHP, Typescript (JavaScript), C#, and Bash.
Future Directions
Meta AI has partnered with Microsoft to make LLaMA 2 available in the Azure AI model catalog, enabling developers using Microsoft Azure to build with it and leverage their cloud-native tools. It is also optimized to run locally on Windows, providing developers a seamless workflow as they bring generative AI experiences to customers across platforms.
BLOOM LLM
BLOOM, developed by BigScience, is a groundbreaking open-source LLM. With its 176 billion parameters, BLOOM can generate text in 46 natural and 13 programming languages. It was trained on the ROOTS corpus. This makes it the world’s largest open multilingual language model. It also includes many underrepresented languages such as Spanish, French, and Arabic in its training, making it a more inclusive model.
BLOOM resulted from a year-long collaboration involving over 1000 researchers from more than 70 countries. The project was conducted in complete transparency, with researchers sharing details about the data it was trained on, its development challenges, and how they evaluated its performance.

BERT LLM
BERT, developed by Google, is an open-source LLM revolutionizing natural language processing (NLP). Its unique bidirectional training lets it learn from text context on both sides, not just one.
BERT stands out for its transformer-based architecture and masked language model (MLM) objective. It masks input tokens, predicting their original forms from context. This bidirectional information flow helps BERT grasp word meanings more comprehensively.
BERT trained on vast text corpora – 800 million words from BooksCorpus and 2.5 billion from English Wikipedia. It comes in two versions: BERT-Base, with 12 layers and 110 million parameters, and BERT-Large, which has 24 layers and 340 million parameters.
BERT’s adaptability allows it to be fine-tuned with just an extra output layer, fitting a range of tasks from question answering to language inference. It integrates seamlessly with TensorFlow, PyTorch, and other frameworks, available in the TensorFlow Model Garden.
However, BERT’s power comes with high computational demands, a barrier for some. Its bidirectional nature also limits its use in tasks like sequential text generation.
In the NLP community, BERT has gained widespread recognition for its versatility and effectiveness. It has inspired a series of variants like RoBERTa, DistilBERT, and ALBERT, further enriching the field.

OPT-175B LLM
OPT-175B, developed by Meta AI Research, is an open-source LLM with 175 billion parameters. The model was trained on a dataset containing 180 billion tokens and exhibits performance comparable to GPT-3 while only requiring 1/7th of GPT-3’s training carbon footprint.
Key Features and Capabilities
OPT-175B is a decoder-only pre-trained transformer, part of a suite of models ranging from 125 million to 175 billion parameters. It is designed to capture the scale and performance of the GPT-3 class of models.
The model is capable of remarkable capabilities for zero- and few-shot learning. It was trained using the Megatron-LM setup.
The release of OPT-175B has been met with excitement in the AI community, as it provides researchers with unprecedented access to a powerful LLM.
However, it’s worth noting that while the release adds an unprecedented level of transparency and openness to the development of LLMs, it does not necessarily democratize them due to the significant computational resources required.

XGen-7B LLM
XGen-7B (7 billion parameters), Salesforce’s entry into the arena of LLMs, marks a significant step forward in the field.
Key Features and Capabilities
XGen-7B’s capability to process up to 8,000 tokens far exceeds the standard 2,000-token limit. This extended range is pivotal for tasks needing a deep understanding of longer narratives, like detailed conversations, extensive question answering, and comprehensive summarization.
The model’s training on a diverse array of datasets, including instructional content, equips it with a nuanced understanding of instructions. Variants like XGen-7B-8K-base and XGen-7B-inst are specifically fine-tuned for long context lengths and instructional data, enhancing their effectiveness in specialized tasks.
Development and Training
XGen-7B underwent a rigorous two-stage training process, involving 1.5 trillion tokens. This blend of natural language and code data is a distinctive feature, enabling the model to excel in both linguistic and code-generation tasks.
Following the LLaMA training recipe and architecture, it also explored “loss spikes” during its training, reflecting a commitment to tackling complex challenges in model training and optimization.
Accessible through Hugging Face Transformers, XGen-7B is versatile, compatible with platforms like Amazon Web Services. Despite its advanced capabilities, is not immune to issues like biases, toxicity, and hallucinations – common challenges in the realm of LLMs.

Falcon-180B LLM
Falcon-180B, developed by the Technology Innovation Institute (TII), stands as a colossus among Large Language Models (LLMs) with its staggering 180 billion parameters. It outmatches many of its contemporaries in size and power.
Key Features and Capabilities:
Falcon-180B excels as a causal decoder-only model, adept at generating coherent and contextually relevant text. It’s a polyglot, supporting multiple languages, including English, German, Spanish, and French, with capabilities extending to several other European languages.
The model’s training on the RefinedWeb dataset, a representative corpus of the web, coupled with curated data, imparts it with a broad understanding of diverse content. Its versatility shines in tasks like reasoning, coding, language proficiency assessments, and knowledge testing.
Development and Training:
Falcon-180B’s training, a two-month endeavor on AWS using 384 GPUs, signifies a substantial investment in computational resources. The massive data corpus of 3.5 trillion tokens is a significant leap, quadrupling the data volume used for models like LLaMA.
Its innovative architecture features multi-query attention, optimizing memory bandwidth during inference and making it more efficient.
Deployment and Usage:
Accessible via Hugging Face Transformers, Falcon-180B integrates with PyTorch 2.0, making it a versatile tool for researchers and developers. It’s available for both academic research and commercial applications.
Falcon-180B has garnered acclaim in the AI community for its performance and the transparency of its development. It competes admirably with giants like Google’s PaLM (Bard) and even approaches the capabilities of GPT-4.

Vicuna LLM
Vicuna, developed by LMSYS, is an innovative open-source LLM emerging from the LLaMA model. Designed primarily as a chat assistant, Vicuna has become a key player in research focused on language models and chatbots.
Key Features and Capabilities
Vicuna offers two versions, with Vicuna-13B v1.3 being the latest. Vicuna-13B stands out for its training approach, using around 125K conversations from ShareGPT.com. This ensures a dataset that mirrors real-world interactions, enhancing the model’s relevance and applicability.
Development and Training
Vicuna’s development addresses the need for greater chatbot training and architecture transparency, an area where proprietary models like ChatGPT often fall short. Its training, involving 70K user-shared conversations, leans on Stanford’s Alpaca project framework, tweaked to match Vicuna’s specific data quality and context length requirements.
Deployment and Usage
Accessible through command-line interfaces and APIs via LMSYS, Vicuna is user-friendly, with detailed instructions on GitHub. The model undergoes rigorous evaluation, including standard benchmarks and human preference testing.
Limitations and Considerations
While robust for NLP tasks, Vicuna’s non-commercial license limits its use to non-profit purposes, barring commercial exploitation without explicit permission. Also, the model’s computational demands might be challenging for users with limited resources.
It’s seen as a potential rival to proprietary giants like GPT-4, offering comparable performance without the high costs of closed-source models.

Mistral 7B LLM
Mistral 7B is an open-source LLM developed by Mistral AI. It is a 7.3 billion parameter model that outperforms Llama 2 13B on all benchmarks and surpasses Llama 1 34B on many benchmarks. The model is designed for both English language tasks and coding tasks, making it a versatile tool for a wide range of applications.
Mistral 7B was developed in three months, during which the Mistral AI team assembled a top-performance MLops stack and designed a sophisticated data processing pipeline from scratch.
The model uses Grouped-query attention (GQA) for faster inference and implements a fixed attention span to optimize memory usage during inference. This allows Mistral 7B to save half of the cache memory, making it resource-efficient while maintaining model quality.
Mistral 7B can be accessed and used through various platforms like HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart, and Baseten. The model is released under the Apache 2.0 license, allowing it to be used without restrictions for both research and commercial purposes.
CodeGen LLM
CodeGen, an open-source Large Language Model (LLM) developed for program synthesis, marks a significant stride in AI. Designed to understand and generate code across multiple programming languages, it competes with top-tier models like OpenAI’s Codex. Its unique trait is transforming English prompts into executable code, making it ideal for synthesizing programs from descriptions or examples.
Trained on a combination of natural and programming languages, CodeGen’s training spanned The Pile (English text), BigQuery (multilingual data), and BigPython (Python code). This diverse training resulted in specialized variants: CodeGen-NL for natural language, CodeGen-MULTI for multilingual, and CodeGen-MONO for Python.
The model was trained in varying sizes, with parameter counts ranging from 350 million to 16.1 billion, allowing for a broad comparison with other LLMs. Accessible through platforms like Hugging Face Transformers, CodeGen fits a wide range of coding tasks and is released under the Apache-2.0 license, supporting both research and commercial use. Its training library JAXFORMER and model checkpoints are also open-sourced, further democratizing access to advanced LLMs.

Conclusion
The field of Large Language Models (LLMs) is expanding fast. Open-source models like BERT, CodeGen, Llama 2, Mistral 7B, Vicuna, Falcon-180B, and XGen-7B are leading the way. These models are key in pushing natural language processing forward.
Open-source LLMs are vital. They spark innovation.
They bring transparency to AI development and foster global collaboration. They make AI advances more accessible. These models can be customized and adapted, which is essential for progress in various fields.
The future of LLMs looks bright.
More inclusive, ethical, and powerful models are on the horizon. Continuing to support and develop open-source LLMs is key to ensure the benefits of AI are shared and used globally.
Do check out Carver Agents’ RegWatch – our new AI solution for real-time contextual regulatory risk intelligence, built for risk and strategy executives. Think of it as agentized mid-market LexisNexis. Visit https://carveragents.ai/.