

As a conductor stands poised on the podium, baton aloft, they survey the orchestra before them. Each musician holds a different instrument, a unique voice in the grand symphony they are about to perform. Violins, their strings humming with anticipation, are primed to sing the melody. Cellos stand ready to resonate with harmony, the percussion section is set to dictate the tempo, and the brass section waits to inject dramatic flair.
In this moment, the conductor’s role becomes pivotal: they must blend these distinct sounds into a unified, captivating performance. Each instrument contributes its part, but it is the conductor’s orchestration that creates the symphony.
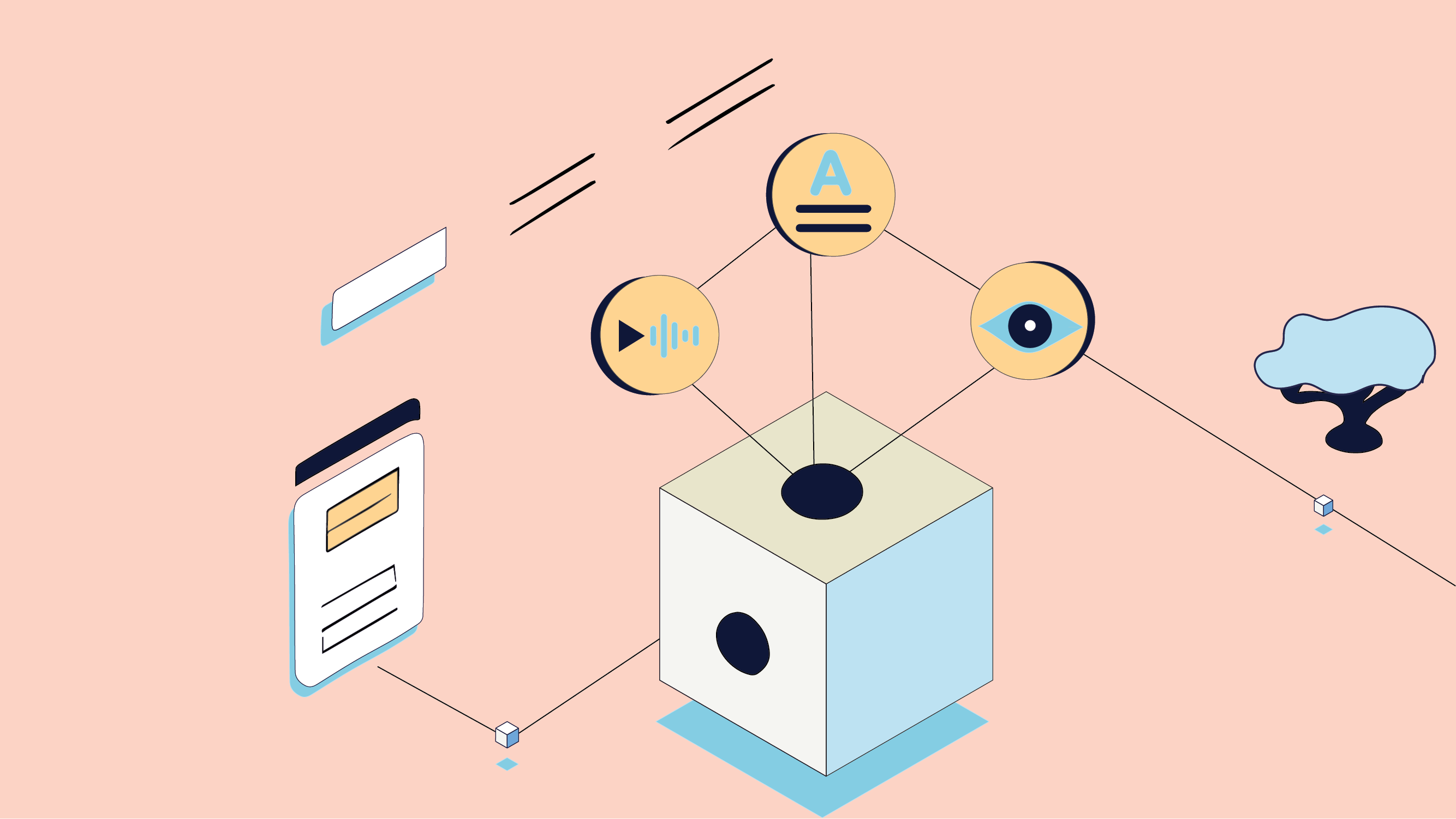
This scenario is a compelling representation of a sophisticated concept in Artificial Intelligence (AI): ‘multimodal learning.’ In this case, the conductor is akin to a multimodal learning model. It takes the diverse ‘voices’ – data from text, images, sound, and more – and harmonizes them. This enables AI systems to perceive the world much like we do, processing a symphony of sensory information simultaneously.
In this fresh Scribble blog, we delve into the world of multimodal learning, where we will explore its nuances, types, real-world applications, challenges, and potential. Ready to take the conductor’s stand?
What is Multimodal Learning?
Multimodal learning in AI is the process of integrating and processing various types of data – text, images, sound, and more – to make informed decisions or predictions. This technique mirrors human cognitive abilities. When we interact with the world, we don’t rely on a single sense; we gather information from multiple sources, interpreting and cross-referencing them for a richer understanding.
Consider, for instance, how a human reads a comic strip. We don’t just read the text or look at the images separately; we combine both for a comprehensive understanding of the story. Similarly, a multimodal AI model could analyze both the written and visual content, leading to more nuanced interpretations than if it were processing each modality in isolation.
At the heart of multimodal learning models are neural networks – sets of algorithms modeled loosely after the human brain that are designed to recognize patterns. In the context of multimodal learning, these neural networks often operate in layers, with each layer responsible for analyzing a different type of data or ‘modality’.
Before we delve deeper into its real-world applications, it is crucial to appreciate the mechanics of multimodal learning. Imagine this – you’re overseeing a social media platform, trying to understand the nuanced content your users post every day. You are in the shoes of the conductor, faced with an ensemble of data types, each playing their tune. This is how a multimodal learning model would approach the situation.
- Data Integration
Initially, each data type is processed individually, much like listening to each section of the orchestra in isolation. In a practical scenario, say you are trying to discern the sentiment behind a user’s post on your platform. A multimodal model would independently process the textual content, any accompanying images, videos, and possibly even emoticons.
- Feature Extraction
Next comes feature extraction, a process of identifying the most valuable ‘notes’ or aspects within each data type. This is akin to a conductor pinpointing the crucial melodies, harmonies, and rhythms in each section of the orchestra. Applying this to our social media example, the AI model identifies key features in the text (keywords, tone), images (objects, colors), and videos (visual context, movement) that are indicative of sentiment.
- Data Fusion
Once the key features are extracted, the multimodal model performs data fusion, where it integrates these features to understand the complete ‘symphony’. The process is like a conductor blending the different musical elements to create harmony. For the AI model, this could mean interpreting how the text, images, and videos in the post relate to each other and provide context. The fusion could be early (combining data at the feature level), late (combining data at the decision level), or hybrid (a mix of the two).
- Model Training and Prediction
The final step involves training the model on this integrated data and then employing it to make predictions. This is where the real magic of multimodal learning happens. By amalgamating multiple data types, the model can make more nuanced and accurate predictions about user sentiment than models that rely on a single data type.
Applications of Multimodal Learning in AI
As we progress towards the real-world applications of multimodal learning, let us highlight the trailblazers — the state-of-the-art models that are currently leading the charge in transforming this field.
CLIP (Contrastive Language–Image Pretraining): CLIP, from the labs of OpenAI, marries text and images through natural language supervision. Trained on a plethora of internet text–image pairs, it adeptly handles a broad spectrum of image and text pairings and is a significant stride towards multi-modal AI models.
DALL-E: DALL-E, another OpenAI creation, spins the wheel in the opposite direction—it generates images from textual descriptions. With an uncanny ability to conjure images of non-existent objects and scenes, DALL-E injects a creative vein into AI.
GPT-4: The latest in OpenAI’s Generative Pretrained Transformer series, GPT-4 adds another dimension by processing and generating not just text but also images. Its broad understanding leads to more contextually relevant outputs and takes us a step closer to AI systems that perceive the world much like humans do.
VQ-VAE-2: DeepMind’s VQ-VAE-2 leverages vector quantization (VQ) and variational autoencoders (VAEs) to generate high-quality images. This model has heralded a significant improvement in image generation capabilities and has been used to produce diverse images, including faces, animals, and objects.
SimCLR: Google Research’s SimCLR uses a type of self-supervised learning known as contrastive learning to learn visual representations from unlabeled images, attaining state-of-the-art performance on several benchmark datasets.
Multimodal learning finds its relevance in various industries where practical applications are crucial. Here are a few fields where it is making a significant difference:
- Healthcare
Multimodal learning allows AI to incorporate various types of data in the healthcare sector — medical histories, lab results, imaging data, and even social and environmental factors. For instance, Google’s DeepMind used multimodal learning for its AI model to predict acute kidney injury up to 48 hours before it happened. By integrating diverse data types, the AI provided more accurate diagnoses, facilitating timely intervention and treatment.
- Autonomous Vehicles
Autonomous vehicles are like rolling data centers, equipped with an array of sensors collecting diverse data types — cameras capturing visual data, LIDAR systems mapping the surroundings in 3D, GPS for positioning, and more. Waymo’s self-driving cars use multimodal learning to process this multi-sensory data in real-time, allowing them to understand their environment, make decisions, and navigate safely.
- Emotion Recognition
Emotion recognition is an intriguing application of multimodal learning — one where AI models analyze facial expressions, voice tones, and speech content to assess a person’s emotional state. An example is Affectiva’s Emotion AI, used by companies in the automotive industry and media testing. It gleans data from both faces and voices to detect nuanced emotions, helping in refining customer experiences or understanding audience reactions to media content.
- E-commerce and Retail
In the era of online shopping, multimodal learning is leveraged to improve the consumer experience and streamline search processes. Platforms like Amazon or Alibaba use multimodal learning algorithms to analyze product images, descriptions, customer reviews, and more. This aids in developing efficient recommendation systems, enhancing image-based searches, and fostering personalized customer experiences. For example, visual search technologies allow customers to snap a photo of a product they like, and the system will provide similar product recommendations by interpreting the image and correlating it with its vast database of product descriptions and pictures.
- Social Media Monitoring
Social media platforms are a goldmine of user-generated text, image, and video data. Multimodal learning aids in extracting valuable insights from this torrent of information. AI models employing multimodal learning are used for various purposes, from identifying trending topics and sentiment analysis to detecting inappropriate content and fake news. Facebook’s AI, for instance, applies multimodal learning to understand and moderate the billions of posts, photos, and videos shared daily on its platform, creating a safer and more relevant user experience.
Limitations and Challenges of Multimodal Learning
Even with its powerful capabilities, multimodal learning has its fair share of challenges. While the system has the potential to be a maestro, it still faces hurdles that prevent it from performing a flawless symphony.
Data Collection and Labeling
The first challenge is the collection and labeling of multimodal data. Sticking with our social media example, gathering a balanced set of user posts that contain varied data types – text, images, videos – is no small feat. Moreover, accurately labeling this data for training purposes is an arduous task. For instance, discerning the sentiment of a post could be subjective and open to interpretation, making the labeling process complex and time-consuming.
Model Complexity
Multimodal learning models are inherently complex due to their need to process and integrate multiple data types. The more data types a model has to handle, the higher the computational requirements. This can become a stumbling block, particularly when dealing with high-dimensional data like images and videos. It requires a delicate balance to ensure the model is robust enough to handle the complexities but not so resource-intensive that it becomes impractical.
Data Fusion
The data fusion process, while being a strength, can also present challenges. Deciding when and how to combine the different data types is nontrivial. Early fusion might cause loss of unique characteristics of individual modalities, while late fusion might not capture the correlations between modalities adequately. Choosing the optimal fusion method for a particular application requires a deep understanding of the data and the problem at hand.
Limited Transferability
Just as a conductor trained in classical music might struggle with a jazz ensemble, a multimodal model trained on one type of data might not perform well when presented with a different type of data. This limitation in transferability requires careful consideration, especially when deploying these models in dynamic real-world scenarios.
Despite these challenges, the future of multimodal learning is promising. With ongoing research and development, we can expect improvements that will enable us to overcome these limitations and fully harness the power of multimodal learning.
The Future of Multimodal Learning
As we round out our symphony, let’s peek into the future, imagining where the conductor—our multimodal AI—might lead us. With developments like the Internet of Things (IoT) and big data analytics in full swing, the possibilities for multimodal learning are expanding at an astonishing pace.
- Internet of Things (IoT): Our homes, cities, and devices are increasingly connected, generating a wealth of data from various modalities. Consider a future smart home, teeming with sensors—motion sensors, heat sensors, cameras, microphones—all working together to create a comfortable and safe living environment. In this case, a multimodal learning model could analyze visual, auditory, thermal, and motion data to understand complex events, such as detecting intruders or responding to a resident’s needs.
- Big Data Analytics: The process of examining large and varied data sets—provide a fertile ground for multimodal learning. As we are able to gather more and more data of different types, the ability to process and learn from this information becomes increasingly critical.
A healthcare app, for instance, might pull together text from doctor’s notes, patient’s symptoms, medical images, lab results, and more. By harnessing these multiple data types, a multimodal model can predict health outcomes more accurately, possibly even uncovering connections that might otherwise remain hidden.
- More Effective Training Methods: Training multimodal models can be challenging due to the complex, varied nature of the data. However, there’s active research in devising methods that can handle these challenges more efficiently. For instance, the paper “Multimodal Machine Learning: A Survey and Taxonomy” discusses various approaches to multimodal learning, including early fusion, late fusion, and hybrid fusion, which can be used to better integrate data from different modalities during training.
- Better Handling of Unseen Modalities: Currently, multimodal models struggle when confronted with a new type of data they haven’t encountered during training. However, researchers are exploring ways to make models more adaptable, allowing them to handle new data types without extensive retraining. The paper “Deep Multimodal Learning: A Survey on Recent Advances and Trends” discusses the concept of zero-shot learning, which is a method that allows models to make predictions for unseen classes or modalities.
- R-Drop: A recent development in the field of AI, R-Drop is a simple yet effective technique for improving the robustness and generalization of neural networks. It uses a regularization method based on the KL-divergence between the output distributions of the same model on the same data point but with different dropout masks. This technique could potentially be applied to multimodal learning to improve the robustness of the models. The paper “R-Drop: Regularized Dropout for Neural Networks” provides a detailed explanation of this technique and shows its effectiveness in various deep learning tasks.
In conclusion, multimodal learning is the cornerstone of the next generation of AI systems. It is the key to creating more intuitive and interactive user experiences, understanding the context and nuances of human communication, and unlocking the potential of the vast and varied data we generate every day. As we continue to advance in the field of AI, the importance of multimodal learning will only grow, opening up new possibilities for innovation and application.
One such application is in the realm of data-driven decision-making. For instance, Scribble Data’s Enrich Intelligence Platform is a testament to how multimodal learning can be leveraged to drive high-impact business decisions. By connecting multiple data sources and leveraging machine learning, it eliminates infrastructure complexities and enables businesses to build data products rapidly and effectively. As we look to the future, it is clear that the symphony of multimodal learning is far from over—there is much more to come.
Do check out Carver Agents’ RegWatch – our new AI solution for real-time contextual regulatory risk intelligence, built for risk and strategy executives. Think of it as agentized mid-market LexisNexis. Visit https://carveragents.ai/.