


The adoption of artificial intelligence and machine learning has paved the way for drastic changes in data-driven enterprises. To optimize business operations, several companies started embracing what came to be known as the modern data stack. Although this approach benefits big tech companies in making superior business decisions, a majority of companies (which operate at medium volume of data, or reasonable scale) struggle to handle the strenuous data management and infrastructure complexities. Consequently, reasonable-scale companies now realize the need for a data stack that can assist them in quickly building machine learning models at a reasonable scale. According to Gartner, 70% of organizations will shift their focus from big to small and wide data by 2025. Usually, reasonable-scale companies do not require large machine learning models for business growth since they do not operate at the same scale as big tech companies like Alphabet and Meta. Most use cases of reasonable-scale companies can be handled with reasonable-scale machine learning models that do not require complex end-to-end MLOps workflows. As a result, the postmodern data stack has started to proliferate among data-driven companies.
What is Modern Data Stack?
Modern data stack (MDS) is a collection of tools and methodologies that assist organizations in handling and leveraging big data. Today, organizations use tools like PyTorch, Apache Kafka, Snowflake, BI tools, and more to simplify their data science workflows. Most of these tools are a result of the open-source community that assists in enhancing the solutions required to handle machine learning and analytics operations effectively. However, since several processes, like collecting and preparing data, building ML models, and deploying models in production, are involved in end-to-end machine learning workflows, organizations soon had to equip several big-data tools. Consequently, a rapid increase in these tools becomes challenging for organizations to handle and avoid disruption as the requirement changes. Therefore, many methodologies like MLOps were embraced by companies to streamline the entire machine learning process. However, companies still struggle to keep up with the changing data science landscape and incorporate new tools to optimize ML workflows. And as the use case of machine learning is increasing within organizations, the complexities will only grow with the modern data stack. While this works for big tech companies that have the resources to maintain machine learning models at scale, reasonable-scale companies grapple with modern data stacks.
Major limitations of Modern Data Stack
-
Skills Gap: Data professionals’ knowledge and the skills gap is one of the biggest challenges in the data science landscape. Companies often struggle to find the right talent since data science is relatively new for educational institutes.
-
Steep Learning Curve: As the requirements change and new tools float in the data science landscape, data professionals must keep up with the latest trends and stay relevant in the domain. A large variety of modern data stacks may offer accessibility and freedom to operate data as you like, yet it creates burnout and attrition among talent.
-
Excessive Accessibility leads to Chaos: Modern data stack gives access to multiple users performing different operations simultaneously. This can cause havoc among teams and a lack of clarity.
-
Certain Tools are not Built for You: Many tools involved in the functioning of MDS were built at big complex organizations like Google, Microsoft, Amazon, and Uber and may or may not fulfill the needs of small to mid sized enterprises.
-
Longer Feedback Loops: As large-scale machine learning initiatives can take a few months to a year, it becomes difficult for organizations to understand if they are on the right path or if the completion of the project would lead to better ROI. It is one of the reasons why 90% of machine learning models fail.
-
Rapid Technology Growth and Diverse Opinions: The data science community is under development, and new minds always thrive to achieve more. That is why the pace of innovations in the field is unmatchable with any other. With this steady growth rate, people are expected to learn and unlearn tools & software promptly. Furthermore, there can be clashing viewpoints on the use case of an approach for what is best for the business.
The Postmodern Data Stack
Similar to the modern data stack, the postmodern data stack focuses on three main computations; transforming & aggregating data, training ML models, and deployment of the model. However, it caters to carrying out machine learning at a reasonable scale, as proposed by Jacopo Tagliabue, Director of AI at Coveo Labs, in his paper ‘You Do Not Need a Bigger Boat.’ The postmodern data stack helps organizations to focus on various business problems and build reasonable-scale machine learning models to make informed decisions. The idea behind the postmodern data stack is to quickly build many machine learning models and optimize numerous business operations. This not only cuts the cost of data-driven initiatives but also allows companies to eliminate data silos created due to modern data stacks.
Since the postmodern data stack is not one size fits all, different experts showcase templates that can simplify the workflow while carrying out data-driven tasks. However, these templates still include some big-data tools but eliminate a chunk of unnecessary big-data solutions you do not require for ML at a reasonable scale. On the other hand, there are SaaS solutions that assist in performing end-to-end machine learning workflow (cleaning data, feature engineering, and deploying models) at a reasonable scale without big data tools.
The postmodern data stack highlights two extraordinary ideas:
1. ML at a reasonable scale
Unlike big tech companies that do not focus on immediate ROI with their data-driven initiatives, reasonable-scale companies build solutions that can bring immediate value to their companies. As a result, the approach to integrating machine learning in their business operations cannot be the same. Organizations that do not serve billions of users need machine learning at a reasonable scale. Often reasonable-scale companies’ customers or users range between a thousand to a few million, thereby they do not have to manage data at terabytes or petabytes scale. In such cases, the ideal approach is to avoid the modern data stack and embrace the postmodern data stack to remain agile and avoid unnecessary expenditures.
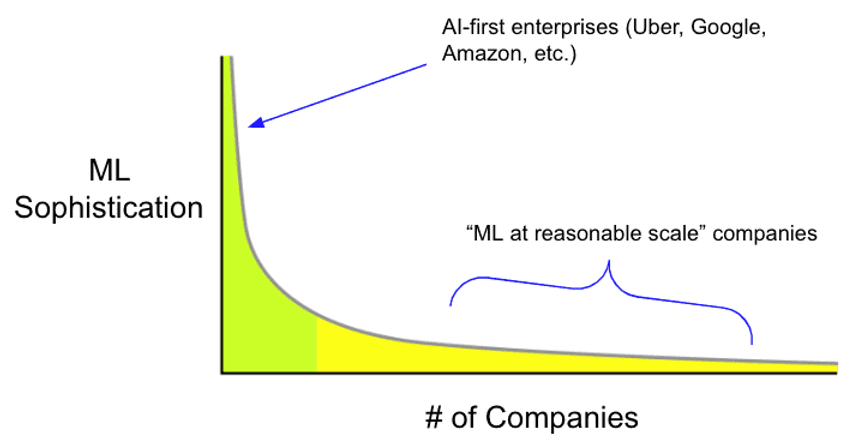
Long-tail distribution of “ML at reasonable scale” companies (Source: Mihail Eric)
Some of the significant factors to consider ML at a reasonable scale:
-
Smaller Team size: Big tech companies often have thousands of data professionals to build numerous large-scale machine learning models for different use cases. However, reasonable-scale companies have limited talents who can take up projects for optimizing business operations with machine learning models. If a small team starts relying on the modern data stack, it will take several months or even a year to take a data-driven project from idea to production. This would be highly inefficient for reasonable-scale companies.
-
Data Volume: Compared to the big tech companies, the volume of data collected by reasonable-scale companies is massively less. However, by embracing the modern data stack, they needlessly increase the time to market (TTM). With a postmodern data stack, reasonable-scale companies can operationalize their ML-based solutions in days or weeks instead of months. The key to carrying out machine learning at a reasonable scale is to make the most out of the company’s data rather than always working with big-data.
-
Monetary Impact: Unlike big tech companies that spend extensively on modern data stack and computing resources, reasonable-scale companies do not have massive budgets for projects. Therefore, reasonable-scale companies fail to harness the power of machine learning in many use cases across the industry with modern data stacks. However, only 30% of the use cases fall under the priority category for companies, and another 70% are in the ‘may be’ category. To optimize costs, companies only focus on 30% and ignore a major source (maybe bucket) of value. This is where Sub-ML, an approach to working with different use cases with small data, helps leverage machine learning capabilities at reasonable-scale companies. There is a broader gap left between the traditional practices – business intelligence and machine learning – since both are at the opposite end of the spectrum in terms of the size and complexity of the data. Instead of focusing only on a few projects with the modern data stack, reasonable-scale companies can use postmodern data stacks and optimize several business processes, which they would ideally have ignored with the modern data stack approach. “At Scribble Data, we see this as the primary way by which ML will scale in future,” said Venkata Pingali, Co-Founder and CEO at Scribble Data.
2. MLOps without the Ops
MLOps is significantly contributing toward the development of machine learning-based solutions. It ensures that organizations can incorporate all necessary checks like data privacy, security, and more while building superior machine learning applications. However, suppose you are building machine learning at a reasonable scale. In that case, you can reduce the dependency of operations in MLOps by decreasing the dependency on complex infrastructure that comes with a modern data stack. And since MLOps is adopted to avoid mistakes, it doesn’t allow you to innovate at a later stage of the development of the models, which is contrary to what the postmodern data stack does – build reasonable scale models quickly for different use cases. A postmodern data stack enables you to fail and learn quickly to eventually make better decisions. This not only reduces the cost of failure but also helps identify new opportunities to leverage machine learning in different business operations.
-
Democratize Machine Learning: Since the postmodern data stack reduces the complexities of building models, you can start implementing ML-based solutions in different departments and help teams make better decisions within days or weeks.
-
Automation: Today, even the postmodern data stack requires expertise to build machine learning models. But, as the framework of the postmodern data stack is straightforward, common business use cases can be automated through templates.
Does this mean that the Modern Data Stack is dead?
While the modern data stack might not be relevant for most reasonable-scale companies, it will still add value to big tech organizations. However, big tech companies will also start using postmodern data stacks to make the most out of their data. With the postmodern data stack, even big tech companies can optimize their internal operations through reasonable-scale machine learning models.
At Scribble Data, we had discovered fairly early that data-driven solutions for long tail use cases is the way forward, and have been strongly supporting the adoption of the postmodern data stack. Our Enrich Intelligence Platform assists companies in reducing friction in the consumption of data and accelerates the journey of data to decisions, spanning across a wide variety of use cases, job titles, and verticals. Enrich enables you to prepare quality data with feature engineering, make it decision-ready with modeling and scoring capabilities, and also consume this prepared data with purpose built apps that can solve a wide variety of business use cases such as anomaly detection, scenario planning, benchmarking, and more. Its full stack approach to feature engineering has helped organizations achieve 5x faster time to value.
Looking Ahead
As every organization realizes the limitations of the modern data stack after initial adoption, the postmodern data stack is ready to take over the data science landscape and assist companies in achieving their business goals quickly. And since the impact on the ROI of the postmodern data stack can be witnessed immediately, it is most likely that its adoption will be faster than the modern data stack. Any organization can quickly embrace postmodern data stacks, deploy in a few days and reap the results in a few weeks.
Do check out Carver Agents’ RegWatch – our new AI solution for real-time contextual regulatory risk intelligence, built for risk and strategy executives. Think of it as agentized mid-market LexisNexis. Visit https://carveragents.ai/.