


In every epoch, some moments redefine the course of human history.
The discovery of fire illuminated the dark. The invention of the wheel set humanity in motion. The creation of the printing press unfurled the banners of knowledge across the globe.
Unironically, we may be standing at the threshold of another such transformative moment with the unveiling of OpenAI’s SORA. This isn’t merely a technological advancement – it’s straight-up sorcery for the digital age. For context, if you somehow showed up in the 1990s (a few short decades ago) with the ability to conjure cinema-quality videos with text prompts, several towns would be named after you.
Frame from video generated by SORA.
LLMs such as SORA interact with our world like children, eyes wide with wonder, grasping at the edges of reality. Each object, sound, piece of text, and color is a puzzle piece in the vast mystery of the world. Through their digital upbringing, these talented children devour vast datasets of information. They learn how to mimic, interpret, and eventually simulate the complex tapestry of human experience and the world we live in.
It’s like watching a child realize that a broom can be more than a cleaning tool—it can be a steed, a rocket, or a friend in their imaginary stories. A world where the act of creation is as simple as the utterance of a sentence.
SORA and its ilk herald a future where ideas leap off the page and into the visual realm, not just seen but experienced. As we delve into the mechanics, the magic, and the implications of these text-to-video models, we confront a future teeming with possibilities and fraught with questions.
How do we navigate this new landscape where reality is no longer a constraint but a canvas? How do we ensure that this powerful tool enhances human creativity rather than undermines it?
We are venturing into uncharted territory, where the ancient art of storytelling merges with cutting-edge technology.
How Do Text-to-Video Models Like SORA Work?
Creating videos from text prompts is a complex process that pairs deep learning with creative generation.
Frame from video generated by SORA.
Here is a brief breakdown of how these text-to-video models work:
Data Collection and Preparation
The first step is to collect and prepare a dataset of clear videos, often from sources like kinetic human action videos. This dataset is crucial as it provides the foundational examples from which the model will learn. For instance, a dataset might include thousands of hours of footage from diverse scenarios to cover a wide spectrum of potential prompts.
Training the Model
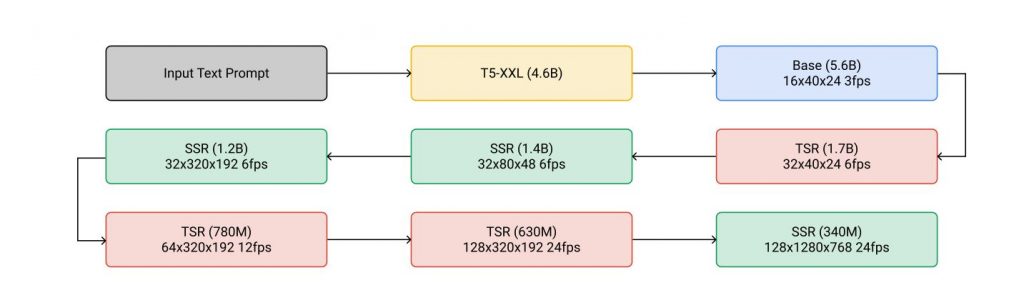
The cascaded sampling pipeline starting from a text prompt input to generating a 5.3-second, 1280×768 video at 24fps. “SSR” and “TSR” denote spatial and temporal super-resolution respectively, and videos are labeled as frames×width×height
The model, typically a convolutional neural network (CNN), is then trained on this dataset. The CNN is responsible for encoding and decoding each frame pixel by pixel, like showing a child many examples of a cat so they can recognize and draw one themselves.
Keywords Extraction

Natural language processing (NLP) techniques extract keywords from the text prompts. If the prompt is “a British shorthair jumping over a couch,” the model identifies “British shorthair,” “jumping,” and “couch” as essential components to be included in the video.
Testing and Refinement
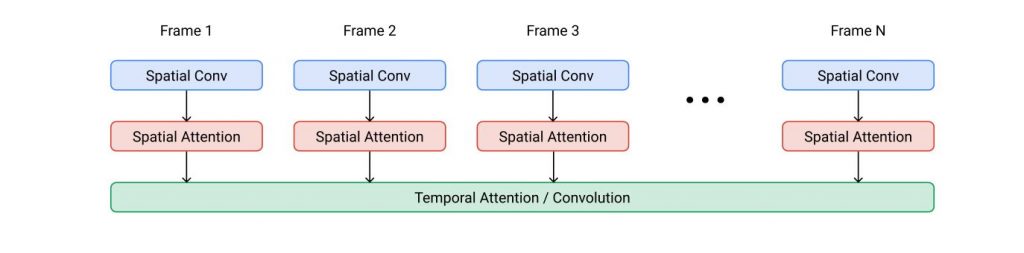
Video U-Net space-time separable block. Spatial operations are performed independently over frames with shared parameters, whereas the temporal operation mixes activations over frames.
The model is tested using a conditional generative model, which includes variational autoencoders (VAEs) and generative adversarial networks (GANs). These models help refine the static and dynamic information extracted from the text to create a coherent video.
Diffusion Process
SORA uses a diffusion process, which starts with a video that resembles static noise. Over many steps, the model refines this noise into the desired video output. This process is like how an artist might start with a rough sketch and gradually refine it into a detailed painting.
Transformer Architecture
Like GPT models, SORA employs a transformer architecture, which is known for its excellent scaling performance. This architecture allows SORA to handle the complex task of video generation effectively.
What Is SORA Capable Of?
Frame from video generated by SORA.
SORA is not just an incremental update to existing technology, it is redefining the boundaries of what is possible with AI. Let us break down its capabilities and try to figure out how SORA functions as a world simulator.
3D Consistency and Long-Range Coherence
SORA’s 3D consistency ensures that as objects and characters move within a video, they do so with a lifelike sense of depth and space. This means if a character walks around a car, SORA renders the car accurately from every angle, much like the meticulous detail in CGI animations. It is a feature that echoes the precision of high-end video game graphics or blockbuster movies, where objects and characters interact seamlessly with their environment.
Interacting with Pre-existing Content
SORA’s ability to animate and extend pre-existing content highlights its versatility. It can transform a still image into a dynamic scene, adding movement and life to previously static elements. This feature blurs the lines between the static and the kinetic, much like the magical elements of the Harry Potter films where portraits and newspapers feature moving images.
High-Quality Output

SORA produces videos in resolutions up to 2048×2048 pixels, setting a new standard for AI-generated media. This high-quality output ensures that videos are not only imaginative but also visually stunning and immersive, rivaling professional-grade production.
Emergent Simulation Capabilities
SORA recreates complex real-world phenomena without explicit programming, simulating the physical world with high fidelity. This ability suggests that scaling video models like SORA is a promising path toward developing simulators that can replicate the physical and digital world with unprecedented accuracy.
Grasp of Cinematic Grammar

Videos from SORA have improved framing.
With a deep understanding of cinematic grammar, SORA can create videos that tell a story with the same visual language used by master filmmakers. It knows when to cut, when to zoom, and how to frame a shot for maximum impact. For example, SORA could replicate the iconic slow-motion scenes from “The Matrix” or the haunting stillness of a Kubrick shot—each frame is a narrative unto itself.
Prompting with Images and Videos

Beyond text-to-video samples, SORA can be prompted with pre-existing images or videos. This versatility enables SORA to perform a wide range of image and video editing tasks, such as creating perfectly looping videos, animating static images, and extending videos forwards or backwards in time.
Video-to-Video Editing

Utilizing diffusion models, SORA can transform the styles and environments of input videos based on text prompts. This technique, known as SDEdit, enables SORA to zero-shot transform video settings, offering a new dimension in video editing.
Connecting Videos
SORA can interpolate between two input videos, creating seamless transitions between videos with entirely different subjects and scene compositions. This capability allows for the blending of disparate video content into a cohesive narrative.
Safeguarding the New Frontier: Text-to-Video Models like SORA

In the surge of text-to-video innovations, SORA stands at the forefront. Yet, this new dawn is not without its shadows. The rise of such technology ushers in complex challenges in ensuring its use remains both safe and beneficial. Let us discuss a few approaches to using this power safely.
The Art of Red Teaming: Imagine squads of thinkers, their task to think like the adversary. Through red teaming, they probe the defenses of text-to-video models with adversarial attacks, hunting for cracks where harm might seep through. This continuous battle of wits is vital, ensuring the technology remains robust against not just today’s threats, but tomorrow’s unknowns.
Content Authenticity: The digital realm now faces a new kind of truth test. Techniques like digital watermarking and metadata, advocated by bodies like the Coalition for Content Provenance and Authenticity (C2PA), offer a beacon of authenticity. These protocols help distinguish AI-generated videos from authentic footage, providing a layer of protection against the misuse of text-to-video models for creating misleading or harmful content.

Developing Misleading Content Detection Tools: Creating and continuously updating classifiers capable of detecting AI-generated content is a proactive measure against the spread of deepfakes and misinformation. By enabling platforms and watchdogs to flag synthetic creations, they ensure the digital world remains anchored in reality.
The Ethical Compass: In a landscape ripe with potential, setting a course that honors ethics is paramount. Guidelines that encompass data dignity, the prohibition of deceit, and the embrace of beneficial uses form the backbone of responsible innovation. Such a moral compass guides both creators and users, illuminating the path of integrity in AI’s application.
Community Custodians: Platforms that serve as the stage for AI’s creations must also act as custodians of community trust. Setting clear ethical guidelines and policies for the use of text-to-video models is fundamental. These guidelines should cover acceptable use cases, data privacy concerns, and the prohibition of creating harmful or deceptive content. Ethical frameworks guide developers and users in navigating the complex landscape of AI ethics, promoting responsible use.
Engaging with External Experts and Stakeholders: The journey of AI is not a solitary venture. Engaging with a chorus of voices—from scholars to the layman—enriches our understanding and fortifies the technology against unforeseen impacts. This collaborative spirit ensures the evolution of text-to-video models is both inclusive and reflective of diverse societal values.
Prioritizing Transparency and Open Communication: Trust in technology is the cornerstone of its acceptance. Transparency about the workings, limitations, and ethical considerations of text-to-video models like SORA builds this trust. An open dialogue not only educates but also empowers users, fostering a community of informed advocates for responsible AI use.
In a realm as dynamic as AI, resting on laurels is not an option. A commitment to perpetual learning, to adapting alongside technological and societal shifts, ensures text-to-video models like SORA remain at the vanguard of innovation, safely.
The Implications of Advanced Text-to-Video Models like SORA on Our World

Sample quality of generated video improves proportionately to training compute.
The introduction of advanced text-to-video models like SORA heralds a new era in digital content creation, with far-reaching implications across societal, business, and technological sectors. Let us explore the potential positive and negative impacts of these technologies.
Societal Implications
Creativity and Art: SORA has the potential to revolutionize artistic expression and creativity, making filmmaking and visual storytelling more accessible. By removing barriers to entry, such as the need for expensive equipment or specialized skills, SORA democratizes content creation, enabling a broader range of voices and perspectives to be heard.
Misinformation and Trust: The ease of creating realistic videos raises significant concerns about deepfakes and misinformation. The proliferation of such content could erode public trust in media and information, making it increasingly difficult to discern truth from fabrication. This underscores the need for robust detection tools and public awareness campaigns.
Privacy and Ethics: Privacy concerns emerge from the ability to create realistic videos of individuals without their consent. Navigating the ethical implications of these capabilities requires clear guidelines and regulations to protect individual’s rights and dignity in the digital age.

Education and Training: SORA offers exciting possibilities for education and training, providing immersive and interactive learning experiences. From historical reenactments to complex scientific concepts, SORA can bring subjects to life in ways that engage and inspire learners.
Business and Industry Implications
Advertising and Marketing: Text-to-video models open up new avenues for personalized and dynamic advertising. Businesses can leverage SORA to create engaging marketing content that resonates with their audience, potentially transforming the landscape of digital marketing.

Film and Entertainment: The film and entertainment industry stands to benefit significantly from SORA. It could introduce new forms of storytelling and streamline production processes, reducing costs and time. This may lead to a surge in independent content creation and innovative narratives.
Journalism and Reporting: SORA could enhance journalism and reporting by creating more engaging news reports or reconstructing events. However, ethical considerations must guide its use, ensuring that such reconstructions are clearly labeled and do not mislead the public.
Gaming and Virtual Reality: In gaming and virtual reality, SORA can create more immersive and dynamic environments, enhancing player experiences. This could accelerate the development of virtual worlds and interactive narratives, pushing the boundaries of what’s possible in gaming.
Technological and Developmental Implications
AI Development and AGI: SORA contributes to the advancement of AI and the pursuit of Artificial General Intelligence (AGI). By simulating the physical and digital world with high fidelity, SORA represents a significant milestone in AI’s ability to understand and interact with the world around us.
Collaboration and Open Innovation: The future development and governance of text-to-video technologies will be shaped by collaboration between AI developers, policymakers, and the public. Open innovation and dialogue are crucial for addressing ethical concerns and harnessing the full potential of these technologies.

Other Notable Text-to-Video Models
In addition to OpenAI’s SORA, other notable text-to-video models have made significant strides in the field of AI-driven content creation. Here’s a brief overview:
Google’s Imagen Video
Google’s Imagen Video is a text-to-video generation model that builds on the success of its predecessor, Imagen, a state-of-the-art text-to-image model. Imagen Video extends these capabilities to video, allowing for the generation of high-fidelity and coherent video clips from textual descriptions. It leverages a diffusion model like SORA’s, capable of creating detailed and temporally consistent videos.
Meta’s Make-A-Video
Meta (formerly Facebook) has developed Make-A-Video, a model that enables users to create short video clips from textual prompts. Make-A-Video focuses on generating videos that are not only visually appealing but also tell a story over the span of the clip. It uses advanced generative models to ensure that the resulting videos are smooth and exhibit a clear narrative flow.
Baidu’s ERNIE-ViLG
Baidu’s ERNIE-ViLG is a large-scale pre-trained model that can generate high-quality video content from text descriptions. It is designed to understand complex prompts and translate them into videos with accurate visual representations. ERNIE-ViLG is part of Baidu’s ERNIE (Enhanced Representation through kNowledge Integration) framework, which aims to improve the understanding and generation capabilities of AI models.
Synthesia
Synthesia is a company that offers AI video generation technology, enabling users to create videos from text with a focus on avatars and virtual presenters. Synthesia’s technology is particularly useful for creating educational content, corporate training videos, and personalized messages, where an on-screen presence is beneficial.
DeepMind’s Phenaki
DeepMind’s Phenaki is a video generation model that emphasizes storytelling and long-term coherence in videos. It is designed to generate sequences that are not only visually consistent but also unfold a story over time, maintaining narrative elements across the video. Phenaki showcases DeepMind’s commitment to advancing the field of generative models in AI.
Runway Gen-2
Runway introduced its Gen-2 model, which is part of a new generation of creative tools that leverage AI to transform text prompts into video content. Runway’s Gen-2 model is designed to be user-friendly, making it accessible to creatives and professionals who may not have a technical background in AI.
Conclusion

The potential of SORA to democratize storytelling, revolutionize industries, and accelerate the path to AGI is as exhilarating as it is daunting. The ethical, societal, and security implications of such technologies beckon us to tread thoughtfully, ensuring that these tools enhance human potential without compromising our values or trust.
The journey ahead is as promising as it is perilous. As we chart this unexplored territory, this is a collective call to wield these models with wisdom, safeguarding against the risks while unlocking the boundless possibilities they hold.
Do check out Carver Agents’ RegWatch – our new AI solution for real-time contextual regulatory risk intelligence, built for risk and strategy executives. Think of it as agentized mid-market LexisNexis. Visit https://carveragents.ai/.